atómová bomba Auto Bambusový les Baščaršija BLEU Bribri Budha Byť Cabécar chrám Cukrovka Dhritarashtra Domorodý Dušičky ECIT eXtreme programming (XP) GitHub Codespaces Godzilla Hirošima Hora Fudži I/ITSEC Informatika Itsukushima Japonsko Jazero Kawaguči Jazyk Jeleň Kabukichō Kjóto Kostarika Koyasan Lemko Minoritizované Nara NDIA Neurónový strojový preklad (NMT) Nindžovia NLP NMT Noví hovorcovia Ohrozený jazyk okuliare Owakudani Podstatné meno Pokoj im vječni Revitalizácia Revitalizácia jazyka Rok Rusínčina Ruština samádhi Sarajevo Shibuya Sloveso spánok Strojový preklad svetelný smog test && commit || revert (TCR) Test Driven Development (TDD) Tokio Topánky Tori no Ichi TrueDark Ukazovacie umelá inteligencia (AI) veľký jazykový model (LLM) Výcvik Zdravie Zem Zámeno Zámená Čierny trh Šindžuku
-

Lemkovské черевікы ⟨čerevikŷ⟩ – „topánky“
Lemkovské slovo черевікы ⟨čerevikŷ⟩ znamená v angličtine „shoes“, v spisovnej ukrajinčine черевики ⟨čerevyky⟩ a v poľštine buty.
-

Lemkovské авто ⟨avto⟩ ‘auto’
Lemkovské podstatné meno stredného rodu авто ⟨avto⟩ znamená v angličtine auto alebo automobil a v poľštine auto alebo samochód. Prízvuk je na prvej slabike.
-

Prezentácia na HCI International 2022
Teším sa, že budem dnes hovoriť na HCI International 2022 Conference v Göteborgu, Švédsko, a predstavím svoj nový príspevok Say It Right: Umelá inteligencia a neurónový strojový preklad posilňujú nových hovorcov pri oživovaní lemkovského jazyka počas sekcie S143: Aplikácie umelej a rozšírenej inteligencie na úlohy súvisiace s jazykovým textom a rečou. Príspevok v zborníku konferencie:…
-

Say It Right: Umelý preklad neurónových strojov posilňuje nových hovorcov na oživenie Lemko (2022)
Abstrakt Neurónový strojový preklad poháňaný umelou inteligenciou by mohol čoskoro oživiť ohrozené jazyky tým, že umožní novým hovorcom komunikovať v reálnom čase pomocou viet, ktoré sú kvantitatívne bližšie k literárnej norme ako vety rodených hovorcov, a to už od prvého dňa ich cesty k obnove jazyka. Zatiaľ čo Silicon Valley investuje obrovské zdroje do technológie…
-

Lemkovský земля ⟨zemlja⟩ „zem“
Nauč sa prekladať, vyslovovať, zapamätať si a používať lemkovské podstatné meno земля ⟨zemlja⟩ „zem“. S etymológiou a podrobnými odkazmi.
-

Lemkovské рік ⟨rik⟩ „rok“
Nauč sa význam, pôvod a skloňovanie lemkovského slova рік ⟨rik⟩ „rok“ a tiež to, ako si ho zapamätať.
-

Lemkovské ukazovacie zámená
Nauč sa preklad, etymológiu a štandardizované skloňovanie lemkovských ukazovacích zámen ⟨tot⟩ „tento“ a ⟨tamtot⟩ „tamten“.
-
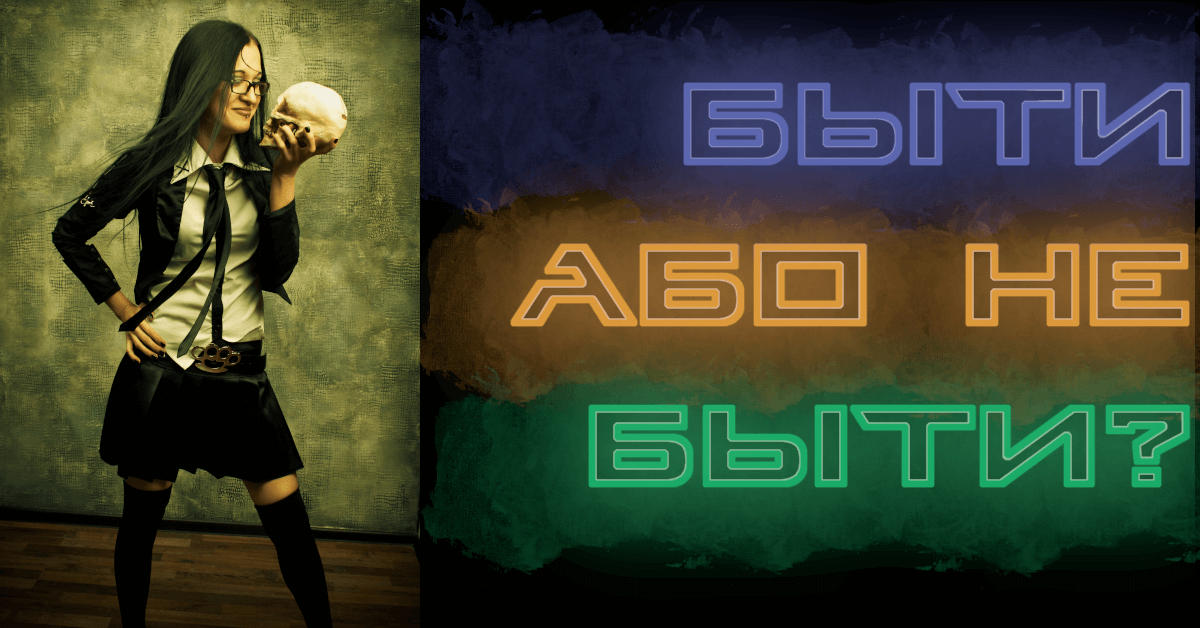
Lemkovské быти ⟨bŷty⟩ „byť“
Byť či nebyť? Быти або не быти? To je otázka — a teraz môžeš v lemkovčine časovať infinitívy, ktoré preslávil úvodný verš Hamletovho monológu, pomocou automatickej prekladovej služby LemkoTran alebo si vlastné spony vytvoriť podľa tohto šikovného DIY návodu. Preklady Lemkovské sloveso быти (vedecká transliterácia: ⟨bŷty⟩) znamená po anglicky „to be“, po poľsky być, v…
-

Nový experiment: Umelá lemkovčina?
Nový experiment testuje hypotézu, že stroj dokáže prekladať do ohrozeného lemkovského jazyka.
