Streszczenie
Gdy zanikają języki mniejszości i lokalne, cierpi na tym bezpieczeństwo narodowe: nie tylko często dokumentuje się znaczący wzrost samobójstw, depresji, cukrzycy, napaści i nadużywania substancji, ale powstaje próżnia, która historycznie była wykorzystywana przez przeciwników. Na przykład, miliony osób ze społeczności mniejszościowych ahistorycznie przyjmują język i/lub tożsamość rosyjską jako własną w Ukrainie, Białorusi, krajach sojuszniczych NATO, a nawet w Stanach Zjednoczonych. Jeśli luki w komunikacji w języku ojczystym pozostaną wyłącznie w rękach przeciwników, wykorzystujących ich długie doświadczenie z tymi językami, NATO pozostaje w znaczącej niekorzystnej sytuacji próbując dotrzeć do tych społeczności. W Europie rany psychiczne zadane częściowo przez utratę języka nie zostały zaleczone przez asymilację. Zamiast tego miasta doświadczają wybuchów izolujących napięć na Zachodzie, a wschodnie populacje są przekonywane przez wrogie mocarstwa, że to one są ich prawdziwymi sojusznikami, którzy ich rozumieją i szanują. Edukacja w języku oficjalnym również nie jest panaceum: w przypadku Ukrainy (a nawet Hiszpanii), nietrywiale różnice między lokalnymi lektami a językiem oficjalnym tworzą możliwości dla przeciwników do podsycania płomieni separatyzmu.
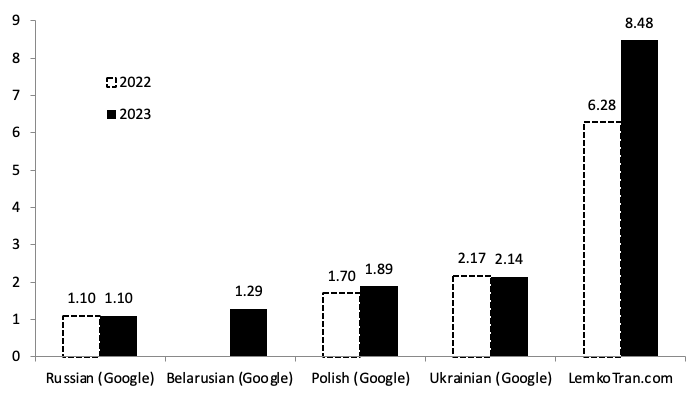
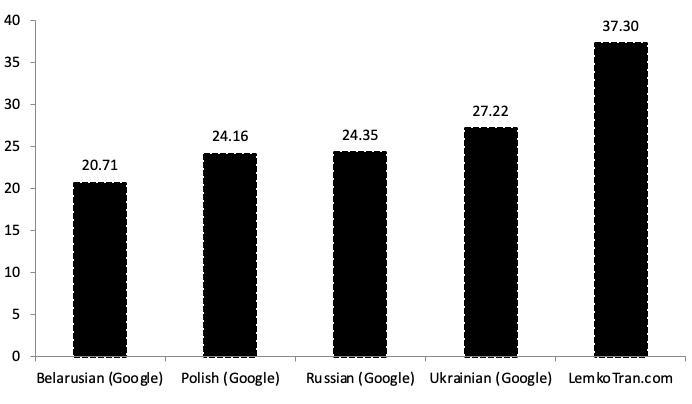
Wykorzystanie silników tłumaczenia maszynowego do wzmocnienia NATO i jego partnerów w szkoleniu rekrutów lub działaniu w terenie w języku najbliższym ich sercom i umysłom może zapewnić natychmiastowe poczucie „swojskości„ i pokazać wielokulturową wizję NATO. Silniki oparte na sztucznej inteligencji i regułach zostały złożone w celu tłumaczenia między oficjalnym językiem Polski a językiem jej rdzennej mniejszości łemkowskiej, która od dawna była celem obcych mocarstw. Silniki zostały ocenione podczas tłumaczenia z łemkowskiego na polski przy użyciu metryk opracowanych przy wsparciu DARPA, uzyskując wynik BLEU (bilingual evaluation understudy) 31,13 i TER (translation edit rate) 54,10. Tymczasem w przeciwnym kierunku silniki uzyskały wynik TER 53,73 i BLEU 29,49, wynik 6,5 razy lepszy niż usługa Google Translate dla pary polsko-ukraińskiej.
Proszę cytować jako: Orynycz, P., i Dobry, T. (2023). Zdobywanie serc i języków: Studium przypadku tłumaczenia z polskiego na język łemkowski. W Materiałach z Konferencji Międzyresortowej/Przemysłowej ds. Szkoleń, Symulacji i Edukacji (I/ITSEC).
Proszę cytować:
Orynycz, P., & Dobry, T. (2023). Winning Hearts & Tongues: A Polish to Lemko Case Study. W: Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?AbID=121223&CID=1001
✅ Ta wersja artykułu została zaakceptowana do publikacji po recenzji naukowej, ale nie jest Wersją Ostateczną i nie zawiera ulepszeń po akceptacji ani żadnych poprawek. Wersja Ostateczna jest dostępna online pod
Wprowadzenie
Wyniki szkoleń mogą skorzystać z wykorzystania tłumaczenia maszynowego dla języków i dialektów rdzennych i mniejszościowych, których użycie jest coraz bardziej i znacząco (p ≤ 0,05) powiązane w literaturze naukowej z bystrzejszymi umysłami, bardziej odpornymi psychikami i lepszym zdrowiem, nie wspominając o sześciokrotnie niższych wskaźnikach samobójstw (Hallett i in., 2007, s. 398). Używanie języka dziedziczonego może chronić przed wpływami obcych przeciwników, a na teatrze północnoatlantyckim może zapobiec przyjmowaniu przez docelowe populacje rosyjskich lub innych ahistorycznych tożsamości etnolingwistycznych podczas radzenia sobie z dewastującymi skutkami utraty języka. Podczas gdy lokalizacja materiałów na lokalne dialekty i języki mogła wcześniej przekraczać możliwości zniszczonych wojną społeczności i rządów, dzięki niedawnym przełomom w sztucznej inteligencji i lingwistyce obliczeniowej, możliwe jest teraz rozważanie przystępnych cenowo urządzeń, które są tańsze, szybsze i lepsze niż ludzie w tłumaczeniu na nisko-zasobowe języki rdzenne i mniejszościowe.
Problem utraty języka nie ogranicza się do Europy. Chociaż globalna sytuacja zagrożenia języków może nie być tak dramatyczna, jak sugerowały dostępne dane z początku lat dziewięćdziesiątych, dostępne statystyki nadal malują ponury obraz. W często cytowanej pracy nazwanej przez Simmonsa i Lewisa (2013) „wielkim językowym wezwaniem do działania„, Krauss ostrzegał w 1992 roku, że od połowy do 90% języków świata miało wymrzeć w tym stuleciu. Ponadto stwierdził „udokumentowany wskaźnik destrukcji„ wynoszący 90% języków rdzennych w anglosfery, gdzie dominuje język angielski, oraz szacowany 50% wskaźnik wymierania dla całego Związku Radzieckiego, gdzie dominował język rosyjski (Krauss, 1992, s. 5). Dwadzieścia lat później Simmons i Lewis (2013) wykorzystali zaktualizowane dane, aby oszacować, że 1360 z 7103 żywych języków (19%) nie jest przekazywanych następnemu pokoleniu (s. 12), a wskaźnik ten wzrasta do 30% w Europie Wschodniej (s. 13).
Neuronauka i Wyniki Uczenia się
Najnowsze badania wskazują, że używanie języka ojczystego może oznaczać, że więcej przepustowości umysłowej jest dostępne do nauki, a wyniki testów znacząco się poprawiają. Badanie przeprowadzone w Instytucie Badań Mózgu McGoverna kierowane przez naukowców z Massachusetts Institute of Technology (MIT) na początku tego roku zaobserwowało stosunkowo niską reakcję mózgu na bodźce w języku ojczystym, mierzoną techniką funkcjonalnego rezonansu magnetycznego (fMRI) (Malik-Moraleda i in., 2023). Jako wyjaśnienie, badacze zasugerowali, że ekspertyza zmniejsza ilość mocy mózgu wymaganej do wykonania zadania (Mesa, 2023). W niedawnym badaniu dla Banku Światowego, Soh, Del Carpio i Wang (2021) stwierdzili, że używanie nieojczystego języka nauczania może być niekorzystne, szczególnie dla mężczyzn. W badaniu, wyniki testów z matematyki i nauk ścisłych wśród uczniów w Malezji znacząco spadły po zmianie języka nauczania z malajskiego na angielski (Soh i in., 2021, ss. 4, 17, 18–19).
Bezpieczeństwo Narodowe
Według wykładowców Szkoły Operacji Specjalnych NATO White’a i Overdeera, Rosja może wykorzystywać podziały etniczne w społeczeństwach docelowych jako dźwignię wojny hybrydowej w próbie osiągnięcia celów polityki zagranicznej (2020, s. 31-33), przy czym różnice etnolingwistyczne są „łatwo dostępne i łatwe do zaostrzenia„ (s. 40). Poniżej badane jest podżeganie i wykorzystywanie konfliktów etnolingwistycznych zarówno w Europie zachodniej, jak i wschodniej.
Hiszpania: Katalonia
Publiczne używanie języka katalońskiego, języka mniejszościowego używanego w północno-wschodniej Hiszpanii, było zakazane przez rząd Franco do 1975 roku (Miller & Miller, 1996, s. 113). Zamiast rozwiązać konflikt, polityka ta mogła spowodować jego zaognienie. W artykule dla The New York Times, Schwirtz i Bautista (2021) cytowali europejski raport wywiadowczy z czerwca 2020 roku, twierdzący, że elitarna Jednostka 29155 rosyjskiego wywiadu wojskowego była obecna w Katalonii w czasie referendum niepodległościowego w 2017 roku, gdy „tajna grupa protestacyjna„ Tsunami Democràtic okupowała lotnisko w Barcelonie i zablokowała główną autostradę łączącą Hiszpanię z jej północnymi sąsiadami. Trzy dni później, pułkownik rosyjskiej Federalnej Służby Ochrony i bliski krewny wysokiego doradcy prezydenta, głęboko zaangażowanego w rosyjskie wysiłki wspierania separatystów na Ukrainie, przyleciał z Moskwy na sesję strategiczną, aby omówić kataloński ruch niepodległościowy (Schwirtz & Bautista, 2021).
Wsparcie Federacji Rosyjskiej dla katalońskiego ruchu niepodległościowego podobno obejmowało nawet ofertę 10 000 żołnierzy i 500 miliardów dolarów amerykańskich w przypadku uzyskania niepodległości (Baquero i in., 2022; patrz także Brunet, 2022, s. 74). Louise I. Shelley z Centrum Terroryzmu, Przestępczości Transnarodowej i Korupcji na Uniwersytecie George’a Masona w Wirginii nazwała kontakty Rosji z przywódcami separatystycznymi w Hiszpanii zgodnymi z wcześniejszym zachowaniem i wyjaśniła: „Powiązania między Katalończykami a Rosjanami sięgają czasów sowieckich. Przed upadkiem ZSRR w Barcelonie odbywały się spotkania wysokiego szczebla z wybitnymi Rosjanami„ (Baquero i in., 2022).
Zachodnia Ukraina
Na Ukrainie, nietrywialnie różnice między lokalnymi lektami a literackim standardem nauczanym w szkołach tworzą okazje dla przeciwników do podsycania płomieni separatyzmu. Według raportu Rating z 2012 roku, tylko 54% etnicznych Ukraińców używało swojego języka dziedziczonego, 29% używało rosyjskiego, a 17% mieszanki obu (s. 9). W tym samym roku, na każdą książkę drukowaną po ukraińsku przypadało dziewięć drukowanych po rosyjsku, a tylko 13% nakładu mediów drukowanych było napisanych po ukraińsku (Moser, 2016a, s. 604).
Dwie dekady temu, coroczny raport Departamentu Stanu Stanów Zjednoczonych o Praktykach w zakresie Praw Człowieka za rok 2002 informował następująco:
Niektóre prorosyjskie organizacje we wschodniej części kraju skarżyły się na zwiększone użycie języka ukraińskiego w szkołach i mediach. Twierdziły, że ich dzieci są w niekorzystnej sytuacji podczas zdawania akademickich egzaminów wstępnych, ponieważ wszyscy kandydaci byli zobowiązani do zdania testu z języka ukraińskiego.
Departament Stanu, 2003, s. 1758
Rusini (Rusini) nadal domagali się statusu oficjalnej grupy etnicznej w kraju. Przedstawiciele społeczności rusińskiej wzywali do utworzenia szkół z językiem rusińskim, wydziału języka rusińskiego na Uniwersytecie w Użhorodzie oraz włączenia Rusinów jako jednej z grup etnicznych kraju w spisie powszechnym z 2001 roku. Według przywódców rusińskich, w kraju mieszka ponad 700 000 Rusinów.
Departament Stanu, 2003, s. 1759
Jako punkt wyjścia dla szerszych kwestii wspomnianych przez Departament Stanu, które wykraczają poza zakres tego artykułu, były członek Ukraińskiego Instytutu Badawczego Harvarda, Michael Moser, wyjaśnił:
Rusinów można prawdopodobnie najlepiej opisać jako pozostałości Rusinów/Rusinów, którzy nie chcieli przyłączyć się do nowoczesnego ukraińskiego ruchu narodowego i językowego… początkowo ta niechęć nie była oparta na żadnej rusińskiej tożsamości w nowoczesnym sensie, ale wynikała z poglądów rusofilskich, że Rusini/Rusini/Małorusini należą do jednego niepodzielnego narodu rosyjskiego i nie było miejsca dla narodu ukraińskiego i języka ukraińskiego.
Moser, 2016b, s.127
W czerwcu 2007 roku w Moskwie została założona na mocy dekretu prezydenckiego „Fundacja Russkij Mir„, która zaczęła finansować „rodaków„ na Ukrainie, przekazując do marca 2011 roku ponad 1 200 000 dolarów amerykańskich (Moser, 2016a, s. 607).
25 października 2008 roku w Teatrze Dramatycznym w Mukaczewie, mieście położonym na dalekim zachodzie Ukrainy, odbyło się zgromadzenie (Wiktorek, 2010, s. 100). Pojawiły się nawet doniesienia o około stu uzbrojonych osobach spoza miasta, znajdujących się na zewnątrz (Ukrajinsʹke nacionalʹne objednannja, 2009; patrz również Wiktorek, 2010, s. 100). Cokolwiek się tam wydarzyło, o godzinie 20:30 tego wieczoru na platformie internetowej rusin.forum24.ru pojawiła się proklamacja „przywrócenia państwowości rusińskiej„ w języku rosyjskim. Wśród skarg wymieniono „zastąpienie rusińskiego języka państwowego ukraińskim galicyjskim, językiem polskiej Galicji, północnego sąsiada Rusinów.„ (2-nd Europаn [sic] Сongress Subсarpathion [sic] Rusyns, 2008).
W okresie poprzedzającym wydanie rozkazu jawnej inwazji armii na Ukrainę w celu przeprowadzenia szeroko zakrojonej „specjalnej operacji wojskowej„, prezydent Federacji Rosyjskiej poświęcił cały akapit „losowi Rusi Podkarpackiej„ w swoim eseju O historycznej jedności Rosjan i Ukraińców:
Osobno omówię los Rusi Podkarpackiej, która po upadku Austro-Węgier znalazła się w Czechosłowacji. Znaczną część miejscowej ludności stanowili Rusini. Chociaż rzadko się o tym teraz wspomina, po wyzwoleniu Zakarpacia przez wojska radzieckie, kongres prawosławnej ludności tego terytorium zadeklarował poparcie dla włączenia Rusi Podkarpackiej do Rosyjskiej Federacyjnej Socjalistycznej Republiki Radzieckiej lub bezpośrednio do Związku Radzieckiego jako odrębnej, Karpacko-Rosyjskiej republiki.
Putin, 2021
W innym incydencie w regionie, dwóch członków polskiej skrajnie prawicowej organizacji Falanga, której członkowie byli obecni wśród rosyjskich separatystów we wschodniej Ukrainie, podpaliło centrum kulturalne węgierskiej rdzennej mniejszości etnolingwistycznej w stolicy regionu, Użhorodzie, w 2018 roku, oblewając je benzyną i wrzucając koktajl Mołotowa (Górzyński, 2018).
Zdrowie i Bezpieczeństwo
Skłonności samobójcze
Zaobserwowano sześciokrotnie wyższe wskaźniki samobójstw w społecznościach, gdzie mniej niż połowa deklaruje znajomość swojego języka dziedziczonego na poziomie konwersacyjnym (Hallett i in., 2007, s. 398). Pozytywnym aspektem jest to, że wskaźniki samobójstw wśród młodzieży spadły do zera we wszystkich przypadkach z wyjątkiem jednego, gdzie większość deklarowała umiejętność prowadzenia rozmowy w swoim języku dziedziczonym (s. 397). W badaniu z 2022 roku przeprowadzonym przez Pezzię i Hernandeza, osoby, które nie mówiły płynnie językiem dziedziczonym, ale których rodzice mówili (s. 95), były najbardziej narażone na myśli samobójcze (s. 98). Jako wyjaśnienie związku między utratą języka a myślami samobójczymi, Pezzia i Hernandez sugerują „stres akulturacyjny lub wykluczenie społeczne„ wynikające z braku akceptacji jako pełnoprawnego członka swojej grupy etnicznej z powodu braku biegłości w jej języku (s. 100).
Depresja
Po uwzględnieniu wieku, płci, wykształcenia, sytuacji finansowej i przynależności do grupy etnicznej, badacze odkryli, że ukrywanie tożsamości poprzez unikanie używania języka dziedziczonego w miejscach publicznych (określane jako unikanie języka) jest statystycznie istotnym (p = 0,006) predyktorem zakwalifikowania jako „osoba w depresji„ ze względu na uzyskanie wyniku 5 lub wyższego w Kwestionariuszu Zdrowia Pacjenta 9 Kroenke’go i Spitzera (Olko i in., 2023, s. 5-6). Jako teoretyczny mechanizm badacze wspomnieli, że dyskryminacja etniczna wywołuje przewlekły stres, prowadząc do uporczywej nadaktywności osi podwzgórze-przysadka-nadnercza i wynikających z tego podwyższonych poziomów czynnika uwalniającego kortykotropinę i kortyzolu, powołując się na prace Willnera (2017) oraz Slavicha i Irwina (2014).
Cukrzyca
Po uwzględnieniu czynników społeczno-ekonomicznych, cukrzyca typu 2 była znacząco (p = 0,005) mniej rozpowszechniona w społecznościach ze znajomością języka rdzennego (Oster i in., 2014, s. 9).
Używanie tytoniu
Wyższy stopień akulturacji do języka angielskiego był znacząco związany z paleniem wśród starszych azjatyckich amerykańskich nastolatków w Nowym Jorku (Rosario-Sim & O’Connell, 2009). W innym badaniu, używanie języka angielskiego w domu było związane z wyższymi wskaźnikami palenia wśród azjatycko-amerykańskiej młodzieży (p = 0,021), podobnie jak wysoka biegłość w języku angielskim (p = 0,040) (Chen i in., 1999, s. 325). Wśród dziewcząt pochodzenia hiszpańskiego, te, które mówiły po angielsku z rodzicami, paliły więcej niż te, które mówiły zarówno po angielsku, jak i po hiszpańsku z rodzicami (p < 0,0001), a także dziewczęta, które mówiły po hiszpańsku z rodzicami (p < 0,01) (Epstein i in., 1998, s. 586).
Używanie substancji i napaść
Według Australijskiego Biura Statystycznego (2011/2012), młodzież aborygeńska w wieku od piętnastu do dwudziestu czterech lat, która posługiwała się językiem rdzennym, była mniej skłonna do używania nielegalnych substancji (16% vs 26%), rzadziej zgłaszała upijanie się w ciągu ostatnich dwóch tygodni (18% vs. 34%) i rzadziej padała ofiarą przemocy fizycznej lub gróźb w ciągu ostatniego roku (25% vs 37%).
Dotychczasowe rozwiązania
Sztuczna inteligencja neuronowa
Przełom w neuronowym tłumaczeniu maszynowym dokonany przez międzynarodowy zespół finansowany przez Agencję Zaawansowanych Projektów Badawczych w Obszarze Obronności (DARPA) w ramach projektu Broad Operational Language Translation (BOLT) (Cho i in., 2014), a także przez Google (Sutskever i in., 2014), doprowadził do powstania silników zdolnych do osiągania wyników jakościowych na poziomie porównywalnym z ludzkimi. Jednakże, szkolenie silników neuronowych wymaga większej ilości danych niż jest zazwyczaj dostępna dla języków o ograniczonych zasobach.
Tłumaczenie maszynowe oparte na regułach
Silniki tłumaczeniowe oparte na regułach z przeszłości były generalnie uważane za marnotrawstwo pieniędzy (Hajič i in., 2000, s. 7), z godnym uwagi wyjątkiem praskiego systemu RUSLAN finansowanego przez założoną przez Sowietów Radę Wzajemnej Pomocy Gospodarczej (RWPG), który produkował tłumaczenia dokumentacji systemów operacyjnych komputerów mainframe z czeskiego na rosyjski (s. 7), przy czym tłumaczenia dwóch na pięć zdań były poprawne, kolejne dwa na pięć zawierały tylko drobne błędy, a tylko jedno na pięć wymagało znacznej edycji lub ponownego tłumaczenia (s. 8).
Główne powody podawane dla pozornego rozczarowania w Pradze wynikami systemów opartych na regułach tłumaczących z czeskiego na rosyjski to fakt, że samo zadanie było zbyt złożone, oraz że czeski i rosyjski nie są wystarczająco blisko spokrewnione, aby takie podejście było opłacalne. Do listy można by dodać nierealistyczne oczekiwania i brak obiektywnych metryk oceny. Tymczasem wyniki tłumaczeń z czeskiego na słowacki i polski, wszystkie bliżej spokrewnione języki zachodniosłowiańskie, były całkiem zachęcające (Hajič i in., 2000, s. 12).
Hybrydowe neuronowe/oparte na regułach tłumaczenie maszynowe
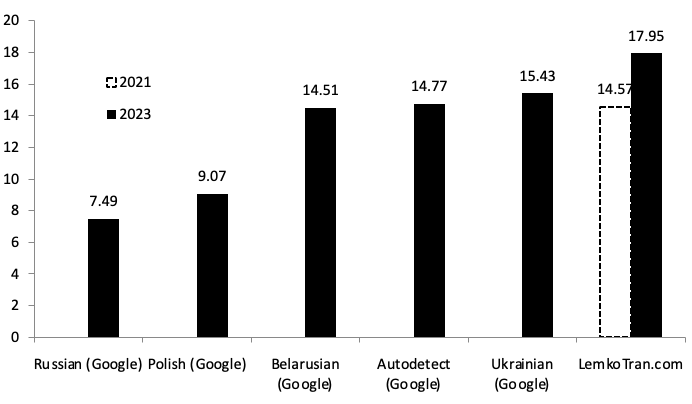
W wynikach przedstawionych na konferencji Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC), silnik oparty na regułach do tłumaczenia z języka łemkowskiego na polski został połączony z silnikiem opartym na regułach do tłumaczenia z polskiego na angielski, co pozwoliło uzyskać pierwsze na świecie opublikowane wyniki tłumaczeń maszynowych z języka łemkowskiego na angielski (Orynycz i in., 2021). W następnym roku uzyskano tłumaczenia w przeciwnym kierunku, modyfikując system i uruchamiając go w odwrotną stronę (Orynycz, 2022). Ulepszenia wprowadzone do tego silnika poprzez jego gruntowną przebudowę i zwiększenie słownictwa doprowadziły później do 35% poprawy jakości tłumaczenia (Orynycz, 2023).
Nowe rozwiązania
System ekspercki tłumaczenia maszynowego opartego na regułach
Silnik wnioskujący został ręcznie zakodowany za pomocą rozwoju sterowanego testami, aby odzwierciedlić prawdy zawarte w bazie wiedzy zebranej w konsultacji z pracami ekspertów dziedzinowych. To podejście pozwala również na ręczne eliminowanie obcych wpływów i usuwanie rusycyzmów i innych zapożyczeń. Konsultowane słowniki obejmowały dwukierunkowy słownik polsko-łemkowski Horoszczaka (2004), słownik łemkowsko-ukraiński Pyrteja (2004), słownik ukraińsko-łemkowski Dudy (2011) oraz glosariusz łemkowsko-polski Riegera (1995), a także jego glosariusz łemkowsko-polski oparty na nagraniach z wioski Bartne (2016). Gramatyki Fontańskiego i Chomiaka (2000) oraz Pyrteja (2013) były konsultowane przy kodowaniu reguł odmiany słów według kategorii gramatycznych takich jak liczba, przypadek i rodzaj.
Sztuczna inteligencja oparta na transformatorach
Przełom w neuronowym tłumaczeniu maszynowym był ściśle związany z wprowadzeniem przez naukowców z Google Brain i Google Research architektury Transformer, która opiera się wyłącznie na mechanizmach uwagi i całkowicie rezygnuje z rekurencji i konwolucji (Vaswani i in., 2017). W ramach tego eksperymentu wytrenowaliśmy modele sztucznej inteligencji oparte na transformatorach do tłumaczenia z polskiego na język łemkowski i, o ile nam wiadomo, jesteśmy pierwszymi, którzy publikują wyniki.
Materiał i metody
Materiał
Dane
Modele sztucznej inteligencji zostały stworzone przy użyciu korpusu obejmującego 1 611 352 słów źródłowych (według licznika Microsoft Word 365) w 112 507 wierszach napisanych przez urodzonych w Polsce rodzimych użytkowników języka łemkowskiego, wraz z ich tłumaczeniami na polski przez interfejs programowania aplikacji (API) Google Cloud Platform Translation skonfigurowany do tłumaczenia jak ze standardowego ukraińskiego przy użyciu neuronowego tłumaczenia maszynowego.
Język łemkowski (znany również jako łemkowski rusiński) genetycznie należy do południowo-zachodniego systemu dialektów ukraińskich, w ramach którego wyróżnia się stałym akcentem na przedostatniej sylabie (Danylenko, 2020). Takie dialekty są rodzime dla terytoriów obecnie znajdujących się pod zarządem Polski i, od 1993 roku, Republiki Słowackiej.
W Polsce międzywojennej rząd wspierał odrębne tożsamości łemkowską, huculską i bojkowską w celu przeciwdziałania ruchowi ukraińskiemu, którego nauczyciele zostali zwolnieni (Moser, 2016b, s. 128). W 1935 roku nauczyciele rusofilscy zostali zastąpieni Polakami, a język łemkowski został ostatecznie usunięty ze szkół w 1937 roku (s. 128). Około dwóch trzecich użytkowników języka łemkowskiego w Polsce zostało deportowanych na Ukrainę w latach 1945-1947, a pozostałe 40 000 do 50 000 przesiedlono głównie na nowo przyłączone, dawne niemieckie terytoria komunistycznej Polski (s. 131). Według wstępnych wyników spisu ludności Polski z 2021 roku, 12 700 osób zadeklarowało narodowość „łemkowską” (Główny Urząd Statystyczny, 2023, s. 3).
Metody
Przetwarzanie wstępne
Najpierw cały tekst został zamieniony na małe litery. Następnie dodano spację przed i po wszystkich znakach niealfanumerycznych. Początkowe i końcowe białe znaki zostały również usunięte z każdego wiersza. Następnie powyższy korpus został przetworzony przy użyciu skryptu Moslema (2023a) do czyszczenia i filtrowania równoległych zbiorów danych (commit db6f441), pozostawiając 33 612 wierszy obejmujących 610 990 słów źródłowych według liczenia przez Microsoft Word 365.
Tokenizacja podwyrazowa
Modele podwyrazowe unigramowe zostały wytrenowane przy użyciu skryptu Moslema (2021a) (commit fbf2488). Następnie te modele zostały wykorzystane do tokenizacji zarówno tekstu źródłowego, jak i docelowego przy użyciu drugiego skryptu podwyrazowego z tego samego commita (Moslem, 2021b).
Podział danych
2000 wierszy z powyższego korpusu zostało wydzielonych do ewaluacji przy użyciu skryptu Moslema (2023b) przeznaczonego do tego celu (commit e6decb7).
Trenowanie modeli sztucznej inteligencji
Modele sztucznej inteligencji zostały wytrenowane przy użyciu wersji TensorFlow zestawu narzędzi OpenNMT do neuronowego tłumaczenia maszynowego, który jest następcą modelu sekwencja-do-sekwencji z uwagą seq2seq-attn Harvardu (Klein i in., 2017, s. 68). Polecenie rozpoczynające pętlę trenowania i ewaluacji zostało uruchomione z automatyczną konfiguracją dla modelu Transformer. Automatyczna ewaluacja została również włączona i ustawiona na uruchamianie co 5000 kroków przy użyciu metryki dwujęzycznej ewaluacji zastępczej (BLEU) oraz eksportowanie modelu, gdy osiągnięto nowy najwyższy wynik. Trenowanie było prowadzone na platformie Google Colabatory wykorzystującej jednostki przetwarzania graficznego NVIDIA A100 i stan wykonawczy o dużej pamięci operacyjnej. Trenowanie było dozwolone przez całą noc.
Silnik wnioskujący
Silnik wnioskujący do tłumaczenia został stworzony na podstawie skryptu klienta Pythona Kleina (commit 2b196ff) (2021), który został zmodyfikowany w celu dostosowania modeli tokenizacji podwyrazowej źródłowej i docelowej, a także optymalizacji odstępów i kapitalizacji, aby lepiej odpowiadać oczekiwaniom modeli sztucznej inteligencji i użytkowników końcowych. Przewidywania tłumaczeń zostały zapisane do pliku w celu późniejszej oceny jakości.
Ocena jakości
Jakość tłumaczeń została oceniona przy użyciu metryk, których rozwój był finansowany przez DARPA: zarówno BLEU (Papineni i in., 2002), jak i Translation Edit Rate (TER) (Snover i in., 2006). Same wyniki zostały obliczone przy użyciu standardowych w branży metod opracowanych w Amazon Research przez Posta (2018).
Wyniki
Wyniki jakości tłumaczenia
Eksperymentalny system ekspercki oparty na regułach przewyższył wszystkie inne pod względem każdej metryki podczas tłumaczenia z polskiego na język łemkowski i odwrotnie.
Jakość tłumaczenia z polskiego na język łemkowski
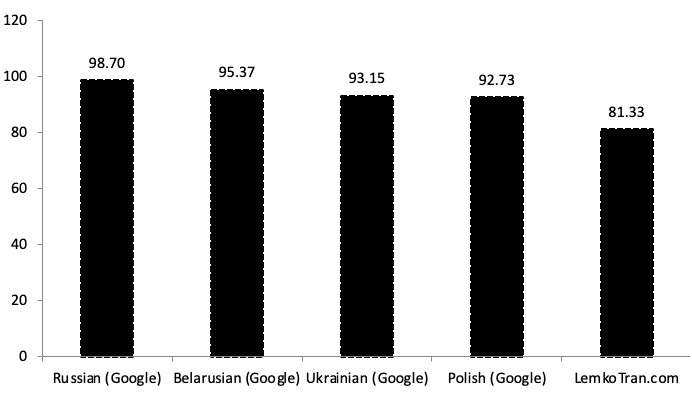
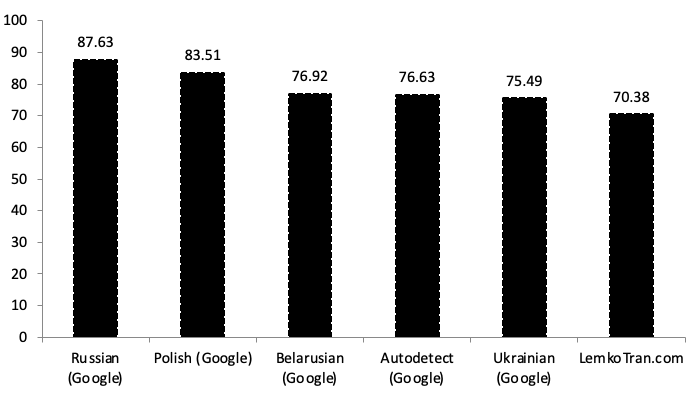
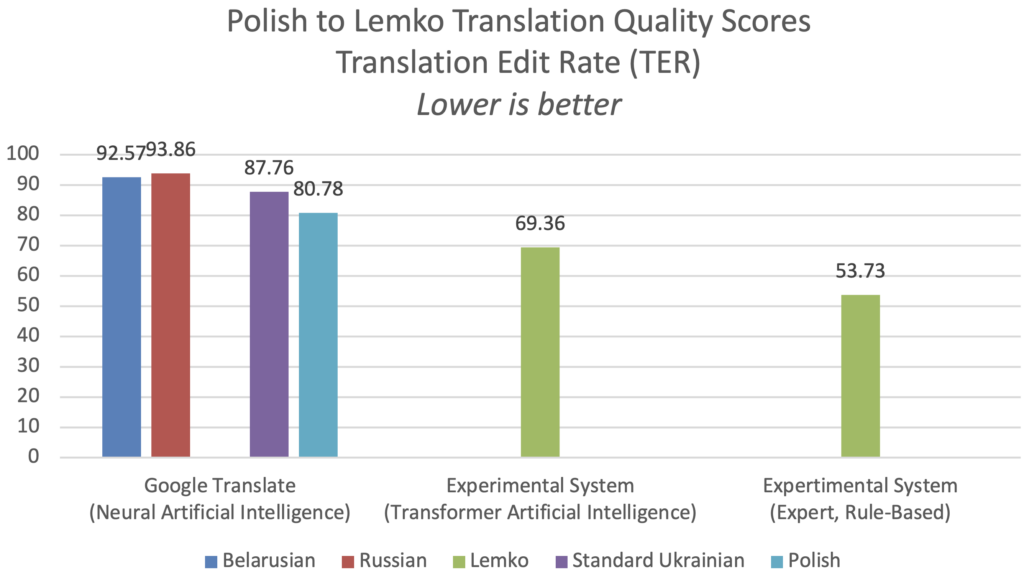
Podczas tłumaczenia z polskiego na język łemkowski, eksperymentalny system ekspercki oparty na regułach osiągnął wynik jakości BLEU 29,49, co jest 6,50 razy lepsze niż usługa tłumaczenia ukraińskiego Google Translate. Tymczasem eksperymentalny system sztucznej inteligencji oparty na transformatorach do neuronowego tłumaczenia maszynowego osiągnął wynik BLEU 15,90 po 30 000 krokach treningu, co było 3,50 razy lepsze niż ukraiński Google Translate. Przy pomiarze za pomocą alternatywnej metryki TER, eksperymentalny system ekspercki oparty na regułach uzyskał wynik TER 53,73, co jest o 61% lepsze niż usługa tłumaczenia ukraińskiego Google Translate.

Jakość tłumaczenia z języka łemkowskiego na polski
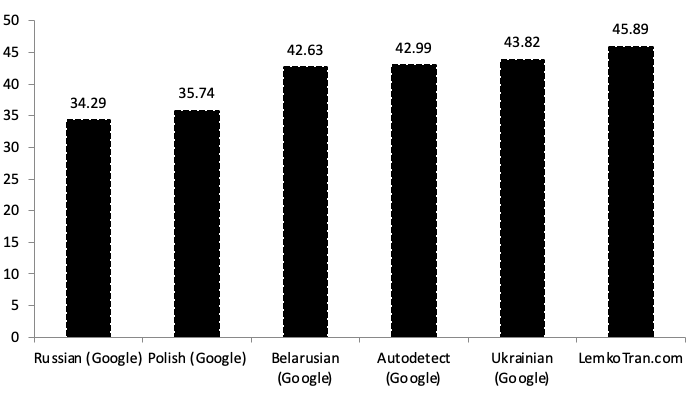
Eksperymentalny system ekspercki oparty na regułach przewyższył wszystkie inne pod względem każdej metryki podczas tłumaczenia z języka łemkowskiego na polski, osiągając wynik jakości BLEU 31,13, co było 1,4 razy lepsze niż wynik usługi tłumaczenia ukraińskiego Google Translate wynoszący BLEU 22,16.
Próbki
| Znaczenie w języku angielskim (tłumacz ludzki) | W tekstach na przykład, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | |||||
| Polski (tłumacz ludzki) | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | |||||
| Prawda: Referencja łemkowska (rodzimy użytkownik) | І они наприклад в текстах, а я головні досліджам тексты, то значыт мам такє джерело, писали: но Австриякы нас мордували, то што зроблят тоты страшны Москалі, котрыма нас страшат? | Na przykład w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: no Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | ||||
| System | Hipotezy tłumaczenia | Wyniki jakości | ||||
| Cyrylica | Transliteracja | BLEU | TER | |||
| Eksperymentalny | System ekspercki (oparty na regułach) | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | 46.32 | 34.48 | |
| Sztuczna inteligencja (Transformer) | Na przykład, w tekstach, a ja głównie badam teksty, mamy źródło, pisali: Austriacy nas mordowali, że to co zrobią stabilizację temu, którymi nas przestraszyli? | Na przykład, w tekstach, a ja głównie badam teksty, mamy źródło, pisali: Austriacy nas mordowali, że to co zrobią stabilizację temu, którymi nas przestraszyli? | 27.65 | 55.17 | ||
| Google Translate | Polski | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | 14.21 | 68.97 | |
| Ukraiński | Na przykład, w swoich tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas wymordowali, co będą robić ci straszni Moskale, którymi nam grożą? | Na przykład, w swoich tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas wymordowali, co będą robić ci straszni Moskale, którymi nam grożą? | 9.43 | 82.76 | ||
| Rosyjski | Na przykład, w ich tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas zabili, co będą robić ci straszni Moskale, którymi nam grożą? | Na przykład, w ich tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas zabili, co będą robić ci straszni Moskale, którymi nam grożą? | 9.43 | 86.21 | ||
| Białoruski | Na przykład, w swoich tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas zabili, co będą robić ci straszni Moskale, którymi nam grożą? | Na przykład, w swoich tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas zabili, co będą robić ci straszni Moskale, którymi nam grożą? | 4.99 | 96.55 | ||
Dyskusja
Implikacje polityczne
Wyniki w zakresie nauki, zdrowia publicznego i bezpieczeństwa mogą ulec poprawie, jeśli materiały edukacyjne, szkoleniowe, informacyjne dla społeczności i inne zostaną zlokalizowane nie tylko w standardowych językach narodowych, ale także w dialektach i językach regionalnych. Aby uniknąć przeciążenia zasobów ludzkich, lingwiści mogliby zająć się post-edycją wyników tłumaczeń maszynowych wykonanych przez systemy eksperckie i sztucznej inteligencji, zamiast tłumaczyć ręcznie. Bardziej przystępny cenowo dostęp do przetłumaczonych materiałów mógłby przynieść poprawę usług społecznych na obszarach niedostatecznie obsługiwanych. Stonewall i in. wymieniają wielojęzyczność, a tym samym inkluzywność, wysoko na liście najlepszych praktyk angażowania niedostatecznie obsługiwanych populacji (2017). Unia Europejska finansuje badania sugerujące, że tłumaczenie maszynowe może być wykorzystane do ułatwienia partycypacji obywatelskiej, a także wzmocnienia zdrowia publicznego i bezpieczeństwa wśród społeczności niedostatecznie obsługiwanych (Nurminen & Koponen, 2020).
Implikacje technologiczne
Wszystko zmierza w kierunku komercyjnie opłacalnego tłumaczenia maszynowego na język łemkowski za naciśnięciem przycisku. Ciągły rozwój systemów eksperckich opartych na regułach, kierowany testami, wydaje się oferować najszybszą drogę do uzyskania nadludzkich wyników jakości tłumaczenia. Systemy sztucznej inteligencji oparte na transformatorach mogą zwyciężyć w długim terminie.
Niektóre modyfikacje procedury treningu sztucznej inteligencji zasługują na eksperymentowanie. Skrypt filtrujący korpus mógł być zbyt gorliwy dla tego zadania i nadmiernie zmniejszyć rozmiar korpusu, utrudniając wydajność. Skrypt ten mógłby zostać pominięty w przyszłym eksperymencie. Nadmierne dopasowanie może hamować wyniki, a być może interwał oceny wynoszący 5000 kroków powinien zostać skrócony. Wykorzystanie eksperckiego systemu opartego na regułach do tłumaczenia korpusów na polski z języka łemkowskiego zamiast usługi Google Cloud Platform mogłoby przynieść lepsze rezultaty. Włączenie modułów automatycznej korekty pisowni mogłoby również globalnie poprawić wyniki.
Rosyjskie i inne obce wpływy językowe mogłyby być zwalczane programowo poprzez usuwanie zapożyczeń za pomocą algorytmów znajdź-zamień. Narodowe akademie językowe i inne instytucje mogłyby uznać takie możliwości za użyteczne. Możliwe, że jakość tłumaczenia osiągnęła już poziom nadludzki, co jest hipotezą, którą można by przetestować w przyszłych eksperymentach.
Deklaracja konfliktu interesów
Główny autor pełni funkcję specjalisty ds. kontroli jakości w projekcie Google Translate w San Francisco.
Referencje
2-nd Europаn [sic] Сongress Subсarpathion [sic] Rusyns [rusin]. (2008, 25 października).MEMORANDUM 2-go Evropejskogo Kongressa Podkarpatskix Rusinov o prinjatii AKTA PROVOZGLAŠENIJA vosstanovlenija rusinskoj gosudarstvennosti [Memorandum Drugiego Kongresu Europejskiego Rusinów Podkarpackich w sprawie Przyjęcia Proklamacji Przywrócenia Państwowości Rusińskiej] [Post na forum internetowym]. Informacionnoe Agenstvo Podkarpatskoj Rusi. IAPR. Forum podkarpatskix rusinov.
http://rusin.forum24.ru/?1-9-0-00000005-000-0-0-1224955832
Australijskie Biuro Statystyczne, (2012). Kultura, dziedzictwo i czas wolny: Mówienie językami aborygeńskimi i wyspiarzy Cieśniny Torresa. Dobrostan Aborygenów i wyspiarzy Cieśniny Torresa: Skupienie na dzieciach i młodzieży. (Oryginalna praca opublikowana w 2011 r.) Pobrano 1 maja 2023 r. z https://www.abs.gov.au/ausstats/abs@.nsf/Latestproducts/1E6BE19175C1F8C3CA257A0600229ADC
Baquero, A., Hall, K.G., Tsogoeva, A., Albalat, J.G., Grozev, C., Bagnoli, L., IStories, & Vergine, S. (2022, 8 maja). Podsycanie secesji, obiecywanie bitcoinów: Jak rosyjski operator nakłaniał katalońskich przywódców do zerwania z Madrytem. Projekt Raportowania o Przestępczości Zorganizowanej i Korupcji (OCCRP). https://www.occrp.org/en/investigations/fueling-secession-promising-bitcoins-how-a-russian-operator-urged-catalonian-leaders-to-break-with-madrid
Brunet, F. (2022). Ekonomia separatyzmu katalońskiego. Cham: Springer Nature Switzerland AG. https://doi.org/10.1007/978-3-031-14451-6
Chen, X., Unger, J.B., Cruz, T.B., & Johnson, C.A. (1999). Wzorce palenia wśród młodzieży azjatycko-amerykańskiej w Kalifornii i ich związek z akulturacją. Journal of Adolescent Health, 24(5), 321-328. https://doi.org/10.1016/S1054-139X(98)00118-9
Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Uczenie się reprezentacji fraz przy użyciu kodera-dekodera RNN dla statystycznego tłumaczenia maszynowego. Materiały z Konferencji 2014 na temat Empirycznych Metod w Przetwarzaniu Języka Naturalnego (EMNLP), 1724–1734 http://dx.doi.org/10.3115/v1/D14-1179
Danylenko, A. (2020). „Karpacko-Rusiński„, w: Encyclopedia of Slavic Languages and Linguistics Online, Redaktor Naczelny Marc L. Greenberg. Sprawdzono online 13 czerwca 2023
http://dx.doi.org/10.1163/2589-6229_ESLO_COM_031960
Departament Stanu (2003). S.Prt. 108-30, Tom I – RAPORTY KRAJOWE O PRAKTYKACH W ZAKRESIE PRAW CZŁOWIEKA ZA ROK 2002 TOM I. Waszyngton, D.C: Biuro Wydawnictw Rządowych USA. https://www.govinfo.gov/app/details/CPRT-108JPRT86917/CPRT-108JPRT86917
Duda, I. (2011). Słownik łemkowski. Tarnopol: Aston.
Epstein, J. A., Botvin, G.J., & Diaz, T. (1998). Akulturacja językowa i efekty płci w paleniu wśród młodzieży latynoskiej. Preventive medicine, 27(4), 583–589. https://doi.org/10.1006/pmed.1998.0329
Fontański, H., & Chomiak, M. (2000). Gramatyka języka łemkowskiego. Katowice: „Śląsk” Sp. z o.o. Wydawnictwo Naukowe.
Główny Urząd Statystyczny (2023). Wstępne wyniki NSP 2021 w zakresie struktury narodowo-etnicznej oraz języka kontaktów domowych. Pobrano 11 czerwca 2023 r. z https://stat.gov.pl/spisy-powszechne/nsp-2021/nsp-2021-wyniki-wstepne/wstepne-wyniki-narodowego-spisu-powszechnego-ludnosci-i-mieszkan-2021-w-zakresie-struktury-narodowo-etnicznej-oraz-jezyka-kontaktow-domowych,10,1.html
Górzyński, O. (2018, 3 marca). Tajna kampania Rosji mająca na celu zaognienie sytuacji w Europie Wschodniej. The Daily Beast. https://www.thedailybeast.com/russias-covert-campaign-inflaming-east-europe
Hajič, J., Hric, J., & Kuboň, V. (2000, kwiecień). Tłumaczenie maszynowe bardzo bliskich języków. W Szósta Konferencja Stosowanego Przetwarzania Języka Naturalnego (str. 7–12). http://dx.doi.org/10.3115/974147.974149
Hallett, D., Chandler, M.J., & Lalonde C.E. (2007): Znajomość języka aborygeńskiego a samobójstwa młodzieży. Cognitive Development. 22(3), 392–399. https://doi.org/10.1016/j.cogdev.2007.02.001
Horoszczak, J. (2004). Słownik łemkowsko-polski, polsko-łemkowski, Warszawa: Rutenika.
Klein, G. (2021). Wnioskowanie z TensorFlow Serving. Pobrano 5 czerwca 2023 r. z https://github.com/OpenNMT/OpenNMT-tf/blob/master/examples/serving/tensorflow_serving/ende_client.py
Klein, G., Kim, Y., Deng, Y., Senellart, J., & Rush, A.M. (2017). OpenNMT: Otwartoźródłowy zestaw narzędzi do neuronowego tłumaczenia maszynowego. W Materiały z 55. Dorocznego Spotkania Stowarzyszenia Lingwistyki Obliczeniowej-Demonstracje Systemów, str. 67–72. https://doi.org/10.18653/v1/P17-4012
Krauss, M. (1992). Języki świata w kryzysie. Language, 68(1), 4–11. https://doi.org/10.1353/lan.1992.0075
Malik-Moraleda, S., Jouravlev, O., Mineroff, Z., Cucu, T., Taliaferro, M., Mahowald, K., Blank, I., & Fedorenko, E. Funkcjonalna charakterystyka sieci językowej poliglotów i hiperpoliglotów za pomocą precyzyjnego fMRI. Cold Spring Harbor Laboratory. Publikacja online przed drukiem. https://doi.org/10.1101/2023.01.19.524657
Mesa, N. (2023, 3 lutego). Twój język ojczysty zajmuje szczególne miejsce w twoim mózgu, nawet jeśli mówisz 10 językami. Science, https://doi.org/10.1126/science.adh0055
Miller, H., & Miller, K. (1996). Polityka językowa a tożsamość: przypadek Katalonii. International Studies in Sociology of Education, 6(1). https://doi.org/10.1080/0962021960060106
Moser, M. (2016a). Polityka językowa we współczesnej Ukrainie (25 lutego 2010–25 lutego 2011). W Nowe przyczynki do historii języka ukraińskiego (str. 601–619). Canadian Institute of Ukrainian Studies Press. https://www.ciuspress.com/product/new-contributions-to-the-history-of-the-ukrainian-language/
Moser, M. (2016b). Rusiński: Nowo-stary język pomiędzy narodami i państwami. W: Tomasz Kamusella, Motoki Nomachi, Catherine Gibson (red.), The Palgrave Handbook of Slavic Languages, Identities and Borders, 124–139. https://doi.org/10.1007/978-1-137-34839-5_7
Moslem, Y. (2021a). Trenowanie modeli SentencePiece dla źródła i celu. Pobrano 4 czerwca 2023 r. z https://github.com/ymoslem/MT-Preparation/blob/main/subwording/1-train_unigram.py
Moslem, Y. (2021b). Podział na podwyrazy plików źródłowych i docelowych. Pobrano 4 czerwca 2023 r. z https://github.com/ymoslem/MT-Preparation/blob/main/subwording/2-subword.py
Moslem, Y. (2023a). Filtrowanie/Czyszczenie równoległych zbiorów danych dla tłumaczenia maszynowego. Pobrano 4 czerwca 2023 r. z https://github.com/ymoslem/MT-Preparation/blob/main/filtering/filter.py
Moslem, Y. (2023b). Podział równoległego zbioru danych na zbiory treningowe, rozwojowe i testowe dla tłumaczenia maszynowego. Pobrano 4 czerwca 2023 z
https://github.com/ymoslem/MT-Preparation/blob/main/train_dev_split/train_dev_test_split.py
Nurminen, M., & Koponen, M. (2020). Tłumaczenie maszynowe i sprawiedliwy dostęp do informacji. Translation Spaces, 9(1), 150–169. https://doi.org/10.1075/ts.00025.nur
Olko, J., Galbarczyk, A., Maryniak, J., Krzych-Miłkowska, K., Iglesias Tepec, H, de la Cruz, E., Dexter-Sobkowiak, E., & Jasienska, G. (2023): Spirala niekorzystnych warunków: Dyskryminacja etnolingwistyczna, stres akulturacyjny i zdrowie w społecznościach rdzennych Nahua w Meksyku. American Journal of Biological Anthropology, 1–15. https://doi.org/10.1002/ajpa.24745
Orynycz, P. (2022, maj). Powiedz to dobrze: Neuronowe tłumaczenie maszynowe AI umożliwia nowym użytkownikom rewitalizację języka łemkowskiego. W Sztuczna Inteligencja w HCI: 3. Międzynarodowa Konferencja, AI-HCI 2022, organizowana w ramach 24. Międzynarodowej Konferencji HCI, HCII 2022, Wydarzenie Wirtualne, 26 czerwca–1 lipca 2022, Materiały (str. 567–580). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-031-05643-7_37
Orynycz, P. (2023, lipiec). BLEUkitne niebo dla rewitalizacji zagrożonych języków: Dokładność tłumaczenia neuronowego AI dla języka łemkowskiego i ukraińskiego wzrasta. W Międzynarodowa Konferencja Interakcji Człowiek-Komputer (str. 135–149). Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-35894-4_10
Orynycz, P., Dobry, T., Jackson, A., i Litzenberg, K. (2021). Yes I Speak… Tłumaczenie maszynowe AI w szkoleniu wielojęzycznym. W Materiały z Konferencji Międzyresortowej/Przemysłowej ds. Szkoleń, Symulacji i Edukacji (I/ITSEC). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?Year=2021&AbID=96953&CID=862
Oster, R.T., Grier, A., Lightning, R., Mayan, M.J., & Toth, E.L. (2014). Cultural continuity, traditional Indigenous language, and diabetes in Alberta First Nations: a mixed methods study. International Journal for Equity in Health, 13(92), 1–11. https://doi.org/10.1186/s12939-014-0092-4
Papineni, K., Roukos, S., Ward, T., & Zhu, W.J. (2002, lipiec). BLEU: a method for automatic evaluation of machine translation. W Proceedings of the 40th annual meeting of the Association for Computational Linguistics (s. 311–318). https://doi.org/10.3115/1073083.1073135
Pezzia, C., & Hernandez, L.M. (2022). Suicidal ideation in an ethnically mixed, highland Guatemalan community. Transcultural Psychiatry. 59(1), 93–105. https://doi.org/10.1177/1363461520976930
Post, M. (2018). A call for clarity in reporting BLEU scores. W Proceedings of the Third Conference on Machine Translation: Research Papers, s. 186–191. Bruksela: Association for Computational Linguistics http://dx.doi.org/10.18653/v1/W18-6319
Putin, V. Ob istoričeskom edinstve russkix i ukraincev [O historycznej jedności Rosjan i Ukraińców]. Pobrano 15 maja 2023 z http://kremlin.ru/events/president/news/66181
Pyrtej, P. (2004). Krótki słownik gwar łemkowskich. Iwano-Frankiwsk: Siversija MB.
Pyrtej, P. (2013). Gwary łemkowskie. Fonetyka i morfologia. Gorlice: Zjednoczenie Łemków.
Rating, (2012). Pytannja movy: rezulʹtaty ostannix doslidženʹ 2012 roku [Kwestia językowa: wyniki najnowszych badań z 2012 roku]. Pobrano 26 sierpnia 2023 z https://ratinggroup.ua/files/ratinggroup/reg_files/rg_mova_dynamika_052012.pdf
Rieger, J. (1995). Słownictwo i nazewnictwo łemkowskie [Słownictwo i nazewnictwo łemkowskie]. Warszawa: Wydawnictwo Naukowe Semper.
Rieger, J. (2016). Mały słownik łemkowskiej wsi Bartne. Warszawa: Wydawnictwo Uniwersytetu Warszawskiego.
Rosario-Sim, M.G., & O’Connell K.A. (2009). Depression and Language Acculturation Correlate With Smoking Among Older Asian American Adolescents in New York City. Public Health Nursing 26(6), 532–542. https://doi.org/10.1111/j.1525-1446.2009.00811.x
Schwirtz, M., & Bautista, J. (2023, 23 września) Married Kremlin Spies, a Shadowy Mission to Moscow and Unrest in Catalonia. The New York Times. Pobrano 16 maja 2023 z https://www.nytimes.com/2021/09/03/world/europe/spain-catalonia-russia.html
Simmons, G.F., & Lewis, M.P. (2013). Języki świata w kryzysie: 20-letnia aktualizacja. W E. Mihas, B. Perley, G. Rei-Doval & K. Wheatley (Red.), Reakcje na zagrożenie języków: Ku czci Mickey’a Noonana. Nowe kierunki w dokumentacji języków i rewitalizacji językowej (str. 3–20). John Benjamins Publishing Company. https://doi.org/10.1075/slcs.142.01sim
Slavich, G.M., & Irwin, M.R. (2014). Od stresu do stanu zapalnego i ciężkiej depresji: społeczna teoria transdukcji sygnałów w depresji. Psychological Bulletin, 140(3), 774–815. https://doi.org/10.1037/a0035302
Snover, M., Dorr, B., Schwartz, R., Micciulla, L., & Makhoul, J. (2006). Badanie współczynnika edycji tłumaczenia z ukierunkowaną anotacją ludzką. W Materiały z 7. Konferencji Stowarzyszenia Tłumaczenia Maszynowego w Amerykach: Artykuły techniczne, (str. 223–231). https://aclanthology.org/2006.amta-papers.25
Soh, Y.C., Del Carpio, X.V., & Wang, L.C. (2021). Wpływ języka nauczania w szkołach na osiągnięcia uczniów: Dowody z Malezji z wykorzystaniem metody kontroli syntetycznej. World Bank Group Policy Research Working Paper 9517. http://hdl.handle.net/10986/35031
Stonewall, J., Fjelstad, K., Dorneich, M., Shenk, L., Krejci, C., & Passe, U. (2017, wrzesień). Najlepsze praktyki angażowania niedostatecznie reprezentowanych populacji. W Proceedings of the Human Factors and Ergonomics Society Annual Meeting (Tom 61, Nr 1, str. 130–134). Sage CA: Los Angeles, CA: SAGE Publications. https://doi.org/10.1177/1541931213601516
Sutskever, I., Vinyals, O., & Le, Q.V. (2014). Uczenie się sekwencyjne z sieciami neuronowymi. Advances in Neural Information Processing Systems 27 (NIPS 2014). https://proceedings.neurips.cc/paper_files/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html
Ukrajinsʹke nacionalʹne objednannja (2009). Zakarpatsʹke UNO obicjaje vlasnymy sylamy protydijaty separatystam [Zakarpacka Ukraińska Organizacja Narodowa obiecuje przeciwstawić się separatystom 1-go maja własnymi siłami] Pobrano 10 czerwca 2023 z https://zaxid.net/zakarpatske_uno_obitsyaye_vlasnimi_silami_protidiyati_separatistam_1_travnya_n1076607
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., & Polosukhin, I. (2017). Uwaga to wszystko, czego potrzebujesz. NIPS’17: Materiały z 31. Międzynarodowej Konferencji na temat Systemów Przetwarzania Informacji Neuronowych, 6000–6010. https://dl.acm.org/doi/10.5555/3295222.3295349
White, D.J., & Overdeer, D. (2020). Wykorzystywanie etniczności w rosyjskich zagrożeniach hybrydowych. Strategos: Czasopismo naukowe Chorwackiej Akademii Obrony 4(1), 31–49. https://hrcak.srce.hr/242087
Wiktorek, A.C. (2010). Rusini Karpat: Konkurencyjne programy tożsamości. Waszyngton, D.C.: Georgetown University. https://repository.library.georgetown.edu/handle/10822/552816
Willner, P. (2017). Model przewlekłego łagodnego stresu (CMS) w depresji: Historia, ocena i zastosowanie. Neurobiology of Stress, 6, 78–93. https://doi.org/10.1016/j.ynstr.2016.08.002