

Honored to have my peer-reviewed paper Say It Right: AI Neural Machine Translation Empowers New Speakers To Revitalize Lemko cited in December 2023 by Alex Jones and Rolando Coto-Solano of Dartmouth College, as well as Guillermo González Campos of University of Costa Rica in their work TalaMT: Multilingual Machine Translation for Cabécar-Bribri-Spanish on Page 107 of the Proceedings of the 3rd Multilingual Representation Learning Workshop in Singapore.
Címke: Nyelvi revitalizáció
-

BLEU Skies for Endangered Language Revitalization: Lemko Rusyn and Ukrainian Neural AI Translation Accuracy Soars
Abstract
Accelerating global language loss, associated with elevated incidence of illicit substance use, type 2 diabetes, binge drinking, and assault, as well as sixfold higher youth suicide rates, poses a mounting challenge for minority, Indigenous, refugee, colonized, and immigrant communities. In environments where intergenerational transmission is often disrupted, artificial intelligence neural machine translation systems have the potential to revitalize heritage languages and empower new speakers by allowing them to understand and be understood via instantaneous translation. Yet, artificial intelligence solutions pose problems, such as prohibitive cost and output quality issues. A solution is to couple neural engines to classical, rule-based ones, which empower engineers to purge loanwords and neutralize interference from dominant languages. This work describes an overhaul of the engine deployed at LemkoTran.com to enable translation into and out of Lemko, a severely endangered, minority lect of Ukrainian genetic classificability indigenous to borderlands between Poland and Slovakia (where it is also referred to as Rusyn). Dictionary-based translation modules were fitted with morphologically and syntactically informed noun, verb, and adjective generators fueled by 877 lemmata together with 708 glossary entries, and the entire system was riveted by 9,518 automatic, codification-referencing, must-pass quality-control tests. The fruits of this labor are a 23% improvement since last publication in translation quality into English and 35% increase in quality translating from English into Lemko, providing translations that outperform every Google Translate service by every metric, and score 396% higher than Google’s Ukrainian service when translating into Lemko.
Please cite as: Orynycz, P. (2023). BLEU Skies for Endangered Language Revitalization: Lemko Rusyn and Ukrainian Neural AI Translation Accuracy Soars. In: Degen, H., Ntoa, S. (eds) Artificial Intelligence in HCI. HCII 2023. Lecture Notes in Computer Science(), vol 14051. Springer, Cham. https://doi.org/10.1007/978-3-031-35894-4_10
Bővebben: BLEU Skies for Endangered Language Revitalization: Lemko Rusyn and Ukrainian Neural AI Translation Accuracy SoarsThis version of the contribution has been accepted for publication after peer review but is not the Version of Record and does not reflect post-acceptance improvements, or any corrections. The Version of Record is available online at https://doi.org/10.1007/978-3-031-35894-4_10. Use of this Accepted Version is subject to the publisher’s Accepted Manuscript terms of use: https://www.springernature.com/gp/open-research/policies/accepted-manuscript-terms.
Table of contents
1 Introduction
1.1 The Problem
Languages are being lost at a rate of at least one per calendar quarter, with such loss set to triple by 2062, and increase fivefold by 2100, affecting over 1,500 speaker communities [1, pp. 163 and 169]. Such outcomes are associated with elevated incidence of illicit substance use [2, p. 179], type 2 diabetes [3], binge drinking, and assault [4], as well as sixfold higher youth suicide rates when fewer than of half of community members have language knowledge [5].
A recent study in the United States found that Indigenous language use has positive effects on health, regardless of proficiency level [6]. An experiment on speakers in Poland has found that use of Lemko moderates emotional, behavioral, and depressive symptoms stemming from cognitive availability of trauma [7].
Artificial intelligence machine translation might be of service in spreading the aforementioned protective effects to heritage speakers by revitalizing dying and Sleeping languages [8, p. 577]. For example, new speakers might produce correct text instantaneously and enjoy reading comprehension using automatic machine translation devices as an aid until full, independent fluency is achieved.
1.2 System Under Study
Language
Lemko is a definitively to severely endangered [9, pp. 177–178] East Slavic lect of southwestern Ukrainian genetic classificability [10, p. 52; 11, p. 39] indigenous to borderlands between the Republic of Poland and Slovak Republic; some have referred to it as Rusyn [11, p. 39; 12].
Eastern boundaries
A unique isogloss differentiating Lemko to the East is fixed paroxytonic (penultimate syllable) stress, a feature shared with Polish and Eastern Slovak dialects [10, pp. 161–162 and 972–973; 11, p. 50; 13, pp. 70–73], making its extent in Eastern Slovakia at least to the Laborec River, with a transitional zone extending thereafter [13, p. 70; 11, p. 50]. Meanwhile in Poland, the historical extent of Lemko reaches at least the Osławica or Wisłok rivers, with a transitional zone beyond them [11, p. 50].
Western boundaries
The historical western boundaries of Lemko are the Poprad and Dunajec rivers [14, p. 459].
Locale
Ancestral villages of native speakers whose interviews comprise the corpus are found within the current administrative borders of today’s Lessor Poland Province, whose capital is Cracow.
Lemko name Transliteration Polish name County Seat Commune Seat Ізбы Izbŷ Izby Gorlice Uście Gorlickie Ґлaдышiв Gladŷšiv Gładyszów Gorlice Uście Gorlickie Чорне Čorne Czarne Gorlice Sękowa Долге Dolhe Długie Gorlice Sękowa Білцарьова Bilcarʹova Binczarowa Nowy Sącz Grybów Фльоринка Flʹorynka Florynka Nowy Sącz Grybów Чырна Čŷrna Czyrna Nowy Sącz Krynica-Zdrój Table 1. Ancestral villages of native speakers interviewed in corpus material. 2 State of the Art
Last year, the world’s first quality evaluation results were published for machine translations into Lemko: BLEU 6.28, which was nearly triple that of Google Translate’s Ukrainian service[1] (BLEU 2.17) [15, p. 570]. The year before, my colleagues and I had published and presented the world’s first results for Lemko to English machine translation: BLEU 14.57 [16].
[1] Disclosure: I work as a paid Ukrainian, Polish, and Russian translation quality control specialist for the Google Translate project. My client’s headquarters are in San Francisco, California.
The engine has been deployed and made freely available at the universal resource locator https://www.LemkoTran.com, where a transliteration engine has been in service since the autumn of 2017. The translation engine was first alluded to in print by Drs. Scherrer and Rabus in the Cambridge University Press journal Natural Language Engineering in 2019 [17].
3 Materials and Methods
3.1 Materials
The experiment was performed on a bilingual corpus comprising Lemko Cyrillic transcripts and English translations of interviews with survivors and children of forced resettlements from ancestral lands in Poland. The transcripts and their translations[1] were aligned across 3,267 segments, with Microsoft Word providing a Lemko source word count of 68,944 and an English target word count of 81,188.
[1] I was hired to produce the transcripts and translate them by the John and Helen Timo Foundation of Wilmington, Delaware, who then donated the work products to my scientific research and development endeavors.
Sources of truth included the dictionaries of Jarosław Horoszczak [18], Petro Pyrtej [19], Ihor Duda [20], and Janusz Rieger [21], as well as the grammars of Henryk Fontański and Mirosława Chomiak [22] and Petro Pyrtej [23].
3.2 Methods
Engine Upgrades
For this experiment, the engine deployed at LemkoTran.com was fitted with newly built generators informed by part of speech, grammatical case, and number for the purpose of producing grammatically and syntactically appropriate translations for 1,585 dictionary entries, about half of which do not inflect in Polish or Lemko, allowing for simple substitution.
Quality Assurance Tests
Quality was ensured by 9,518 tests cross-referenced when feasible with the Lemko codifications, grammars, and dictionaries listed above under Materials. The tests themselves assert that the system translates given utterances in the desired manner.
Description Quantity Noun stem 414 Verb stem 296 Adjective stem 167 Pronoun, personal 87 Pronoun, other 178 Numeral 86 Other dictionary entries 357 Total 1,585 Table 2. System vocabulary. Rule-Based Machine Translation (RMBT)
Text was given a Lemko or Polish look and feel by replacing character sequences, and especially inflectional endings.
Polish Sequence Lemko Sequence Position ować uwaty Final iami iamy Final ają ajut Final ze zo Initial pod pid Initial Table 3. Example character sequence replacements. Translation Quality Scoring
Translation quality was measured per industry standard metrics using the default settings of the SacreBLEU tool invented at Amazon Research by Matt Post [24]. For the sake of comparability, Polish was rendered in Lemko Cyrillic in the same way as the last experiment [15, p. 573].
Bilingual Evaluation Understudy (BLEU)
This n-gram-based metric has enjoyed wide currency for decades. It was developed in the United States at the IBM T. J. Watson Research Center with support from the Defense Advanced Research Projects Agency (DARPA) and monitoring by the United States Space and Naval Warfare Systems Command (SPAWAR) [25].
Translation Edit Rate (TER)
This metric reflects the number of edits necessary for output to semantically approach a correct translation, aiming to be more tolerant of phrasal shifts than BLEU and other n-gram-based metrics. It is determined by dividing a calculation of edit distance between a hypothesis and a reference by average reference wordcount. Its development in the United States was also supported by DARPA [26].
Character n-gram F-score (chrF)
This European metric been shown to correlate very well with human judgments and even outperform both BLEU and TER [27].
4 Results and Discussion
The experimental system, LemkoTran.com, outperformed every Google Translate service by every metric. English to Lemko translation BLEU quality scores improved 35% in comparison with last published results [15], producing results four times better than Google Translate’s next-best offering, its Ukrainian service. Meanwhile, Lemko to English translation quality improved by 23% since last published results [16], achieving BLEU scores 16% higher than the best obtained by Google Translate, which automatically recognized Lemko as Ukrainian 76% of the time, as Russian 16% of the time, and as Belarusian 6% of the time.
4.1 English to Lemko Translation Quality
Scores
The engine deployed at LemkoTran.com bested Google Translate by every metric when translating from English into Lemko. The next-highest scoring system in the experiment was either the output of Google Translate’s Ukrainian service (using the BLEU or chrF metrics) or that of its Polish service (using the TER metric).
BLEU
The translation quality of the system deployed at LemkoTran.com as measured by the most widespread BLEU metric rose to 8.48, a 35% improvement on results last published in 2022 [15], and now quadruple Google Translate’s highest score.
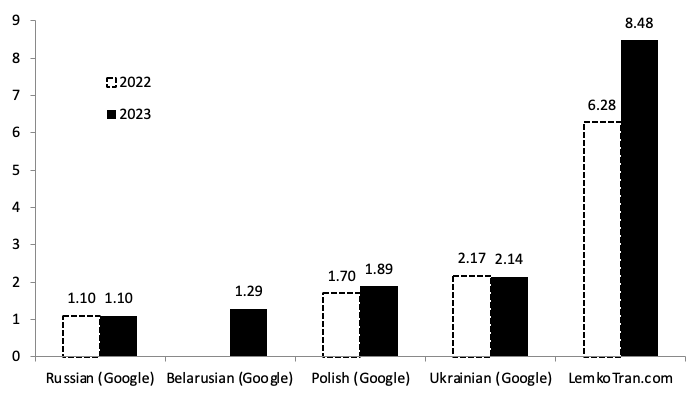
Fig. 1. English to Lemko translation quality as measured by Bilingual Evaluation Understudy (BLEU) score, Google Cloud Neural Machine Translation (NMT) services versus LemkoTran.com. The higher, the better. chrF
The LemkoTran.com engine achieved the best English to Lemko character n-gram f-score (chrF 37.30), which is 37% higher than the next best, Google Translate’s Ukrainian service. Meanwhile, Google Translate’s Russian service scored higher than its Polish and Belarusian counterparts when measured against the Lemko corpus by this metric.
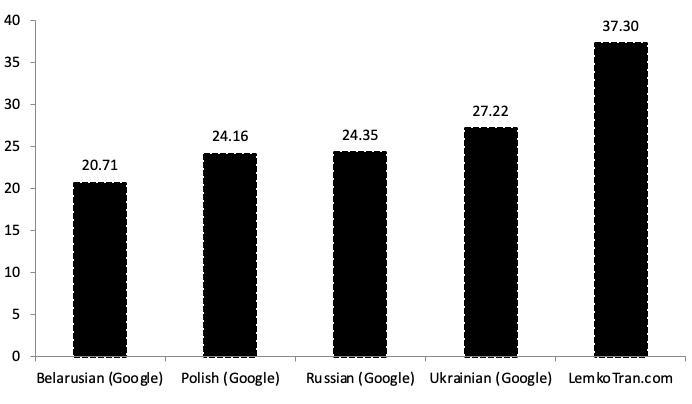
Fig. 2. English to Lemko translation quality as measured by character n-gram F-score (chrF) score, Google Cloud Neural Machine Translation (NMT) versus the experimental system LemkoTran.com. The higher, the better. TER
The LemkoTran.com engine achieved the best English to Lemko Translation Edit Rate (TER), scoring 81.33. Google Translate’s Polish service scored second best, followed closely by its Ukrainian one.
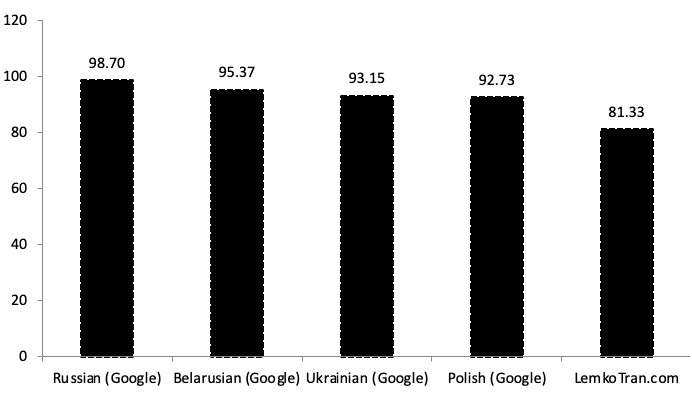
Fig. 3. English to Lemko Translation Edit Rate (TER), Google Cloud Neural Machine Translation (NMT) versus LemkoTran.com. The lower, the better. Samples
Output from the translation systems when fed English is given below.
Input Our children were smart too. But where were they supposed to study? Description Output Transliteration Quality Scores Lemko reference
(native speaker)В нас діти тіж были мудры, але де мали ся вчыти? V nas dity tiž bŷly mudrŷ, ale de maly sja včŷty? BLEU 100
chrF2 100
TER 0Translation into Lemko by
LemkoTran.comНашы діти тіж были мудры. але де мали ся вчыти? Našŷ dity tiž bŷly mudrŷ. ale de maly sja včŷty? BLEU 58.34
chrF2 79.03
TER 27.27Google Translate (control) Translation into Ukrainian Наші діти теж були розумними. Але де вони мали вчитися? Naši dity tež buly rozumnymy. Ale de vony maly včytysja? BLEU 4.41
chrF2 25.80
TER 72.73Translation into Russian Наши дети тоже были умными. Но где им было учиться? Naši deti tože byli umnymi. No gde im bylo učitʹsja? BLEU 3.71
chrF2 16.95
TER 90.91Translation into Polish Наше дзєці теж били мондре. Алє ґдзє мєлі сє учиць? Naše dzjeci tež byly mondre. Alje gdzje mjeli sje učycʹ? BLEU 3.12
chrF2 13.84
TER 100Translation in Belarusian Разумныя былі і нашы дзеці. Але дзе яны павінны былі вучыцца? Razumnyja byli i našy dzeci. Ale dze jany pavinny byli vučycca? BLEU 3.09
chrF2 12.83
TER 100Table 4. Comparisons of translation hypotheses for English input. Input And generally speaking, Lemkos in Poland don’t have a leader, so to speak, who would say something. Description Product Transliteration Quality Scores Lemko reference (native speaker) А воґулі Лемкы в Польщы не мают такого, же так повім, такого лідера, котрий бы штоси повіл. A voguli Lemkŷ v Pol’ščŷ ne majut takoho, že tak povim, takoho lidera, kotryj bŷ štosy povil. BLEU 100
chrF2 100
TER 0Translation into Lemko by LemkoTran.com І генеральні Лемкы в Польщы не мают лидера, же так повім, котрий бы штоси повіл. I heneral’ni Lemkŷ v Pol’ščŷ ne majut lydera, že tak povim, kotryj bŷ štosy povil. BLEU 55.58
chrF2 65.32
TER 29.41Google Translate (control) Translation into Polish І ґенеральнє Лемковє в Польсце нє майон лідера, же так повєм, ктури би цось повєдзял. I general’nje Lemkovje v Pol’sce nie majon lidera, že tak povjem, ktury by cos’ povjedzjal. BLEU 9.26
chrF2 29.29
TER 82.35Translation into Ukrainian І взагалі, лемки в Польщі не мають лідера, так би мовити, який би щось сказав. I vzahali, lemky v Pol’shchi ne mayut’ lidera, tak by movyty, yakyj by shchos’ skazav. BLEU 5.15
chrF2 26.56
TER 82.35Translation into Russian И вообще, у лемков в Польше нет, так сказать, лидера, который бы что-то сказал. I voobšče, u lemkov v Polʹše net, tak skazatʹ, lidera, kotoryj by čto-to skazal. BLEU 2.96
chrF2 25.87
TER 88.24Translation into Belarusian І ўвогуле лэмкі ў Польшчы ня маюць лідэра, так бы мовіць, які б нешта сказаў. I ŭvohule lèmki ŭ Pol′ščy nja majuc′ lidèra, tak by movic′, jaki b nešta skazaŭ. BLEU 2.72
chrF2 18.05
TER 94.12Table 5. Comparisons of translation hypotheses for English input. Lemko to English Translation
Scores
For every metric, the engine deployed at LemkoTran.com outperformed Google Translate, for which translation as if from Standard Ukrainian was always second best, followed by it automatically detecting the source language, then translating as if from Belarusian, and then Polish, with Russian always coming in last place. Google Translate recognized Lemko as Ukrainian 76% of the time, as Russian 16% of the time, as Belarusian 6% of the time, and as sundry languages using Cyrillic alphabets (e.g. Mongolian) the rest of the time.
BLEU
LemkoTran.com scored BLEU 17.95 when translating into English, a 23% improvement on last published results of BLEU 14.57, and 16% higher than Google Translate’s Ukrainian service’s score of BLEU 15.43.
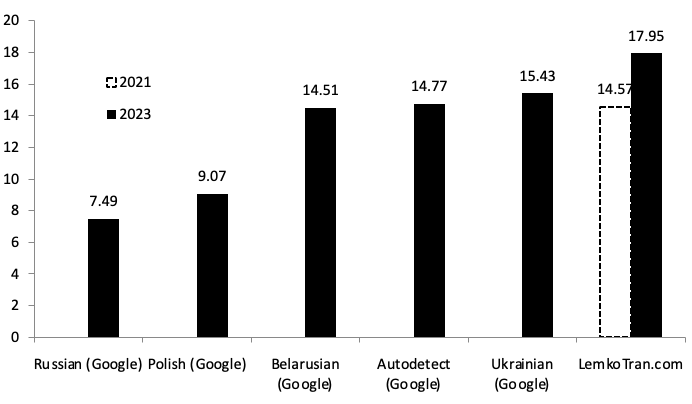
Fig. 4. Lemko to English translation quality as measured by Bilingual Evaluation Understudy (BLEU) score, Google Cloud Neural Machine Translation (NMT) services versus the experimental system LemkoTran.com. The higher, the better. chrF
The engine deployed at LemoTran.com achieved a character n-gram f-score (chrF) of 45.89 when translating into English, which was 5% better than the score of Google Translate’s Ukrainian service.
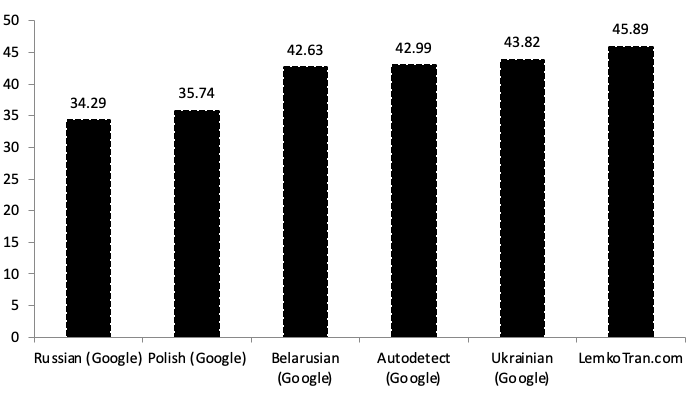
Fig. 5. Lemko to English translation quality as measured by character n-gram F-score (chrF) score, Google Cloud Neural Machine Translation (GNMT) versus the experimental system LemkoTran.com. The higher, the better. TER
LemkoTran.com scored a Translation Edit Rate (TER) of 70.38 translating into English, which was 7% better than the score of Google Translate’s Ukrainian service.
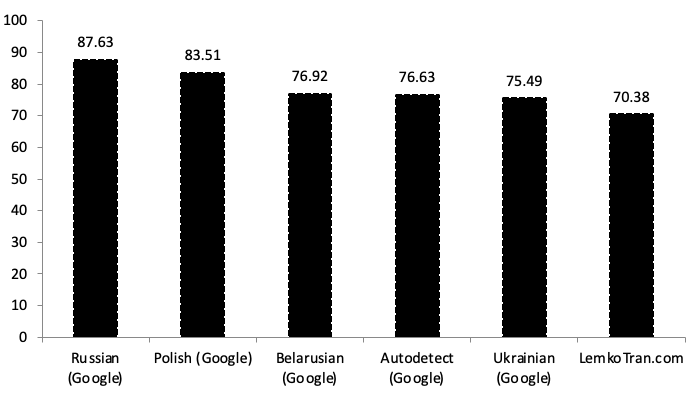
Fig. 6. Lemko to English Translation Edit Rate (TER), Google Cloud Neural Machine Translation (GNMT) versus the experimental system LemkoTran.com. The lower, the better. Samples
Output from the translation systems when fed English is given below.
Description Product Quality
ScoresInput transcription of Lemko spoken by a native speaker Як розділяме языкы, то мала-м контакт з польскым, то не было так, же пішла-м до школы без польского, бо зме мали сусідів Поляків. n/a Transliteration Jak rozdiljame jazŷkŷ, to mala-m kontakt z pol’skŷm, to ne bŷlo tak, že pišla-m do školŷ bez pol’skoho, bo zme maly susidiv Poljakiv. n/a Reference translation by a bilingual professional When it comes to separating languages, I had contact with Polish. It wasn’t like I started school without knowing Polish because we had Polish neighbors. BLEU 100
chrF2 100
TER 0Translation from Lemko by the system at LemkoTran.com When we separate languages, I had contact with Polish, it wasn’t like I went to school without Polish, because we had Polish neighbors. BLEU 45.84
chrF2 69.60
TER 32.00Google Translate (control) from Ukrainian (autodetected with 92% confidence) As we divide the languages, then I had contact with Polish, then it was not like that, and I went to school without Polish, because I had Poles as neighbors. BLEU 15.87
chrF2 54.38
TER 72.00from Belarusian As we separate the languages, then I had little contact with Polish, then it was not like that, but I went to school without Polish, because we had few Polish neighbors. BLEU 11.76
chrF2 58.92
TER 68.00from Russian As we spread languages, then there was little contact with Polish, then it wasn’t like that, but I went to school without Polish, for the snakes were sucid in Polyakiv. BLEU 6.87
chrF2 42.66
TER 92.00from Polish As I spread the language, I have little contact with the Polish language, it wasn’t like that I went to school without Polish, because I will change my little Polish language. BLEU 5.02
chrF2 45.35
TER 84.00Table 6. Comparisons of translation hypotheses for Lemko input. 5 Conclusion
Coupling morphologically and syntactically informed generators to neural engines can improve machine translation quality by at least a third, while also having the side benefit of empowering engineers to purge loanwords and counteract other dominant-language interference, as well as ensure compliance with standards, such as codifications of minority languages. Quality-score glass ceilings imposed by the imperfections inherent to artificial intelligence models can also be shattered through sound engineering. For Lemko, as well as fellow low-resource, Indigenous minority languages, the sky is now the limit for translation quality, as well as revitalization revolutions just over the horizon.
Acknowledgements
I would like to thank Dr. Ming Qian of Charles River Analytics for the inspiration to conduct this experiment, Michael Decerbo of Raytheon BBN Technologies and Dr. James Joshua Pennington for their insightful remarks, as well as Dr. Yves Scherrer of the University of Helsinki for his interest in the project and ideas.
References
- Bromham, L., Dinnage, R., Skirgård, H. Ritchie, A., Cardillo, M., Meakins, F., Greenhill, S., Hua, X.: Global predictors of language endangerment and the future of linguistic diversity. Nature Ecology & Evolution 6, 163–173 (2022). https://doi.org/10.1038/s41559-021-01604-y
- Gonzalez, M., Aronson, B., Kellar, S., Walls, M., Greenfield, B.: Language as a Facilitator of Cultural Connection. ab-Original 1(2), 176–194 (2017). https://doi.org/10.5325/aboriginal.1.2.0176
- Oster, R., Grier, A., Lightning, R., Mayan, M., Toth, E.: Cultural continuity, traditional Indigenous language, and diabetes in Alberta First Nations: a mixed methods study. International Journal for Equity in Health 13, 92 (2014). https://doi.org/10.1186/s12939-014-0092-4
- Culture, Heritage and Leisure: Speaking Aboriginal and Torres Strait Islander Languages. In: 4725.0 – Aboriginal and Torres Strait Islander Wellbeing: A focus on children and youth. Australian Bureau of Statistics (2011). https://www.abs.gov.au/ausstats/abs@.nsf/Latestproducts/1E6BE19175C1F8C3CA257A0600229ADC
- Hallett, D., Chandler, M., Lalonde, C.: Aboriginal language knowledge and youth suicide. Cognitive Development 22(3), 392–399 (2007). https://doi.org/10.1016/j.cogdev.2007.02.001
- Whalen, D., Lewis, M., Gillson, S., McBeath, B., Alexander, B., Nyhan, K.: Health effects of Indigenous language use and revitalization: a realist review. International Journal for Equity in Health 21, 169 (2022). https://doi.org/10.1186/s12939-022-01782-6
- Skrodzka, M., Hansen, K., Olko, J., Bilewicz, M.: The Twofold Role of a Minority Language in Historical Trauma: The Case of Lemko Minority in Poland. Journal of Language and Social Psychology. 39(4) 551–566 (2020). https://doi.org/10.1177/0261927X20932629
- Zhang, S., Frey, B., Bansal, M.: ChrEn: Cherokee-English Machine Translation for Endangered Language Revitalization. In: Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 577–595. Association for Computational Linguistics, Online (2020). http://dx.doi.org/10.18653/v1/2020.emnlp-main.43
- Duć-Fajfer, O.: Literatura a proces rozwoju i rewitalizacja tożsamości językowej na przykładzie literatury łemkowskiej (in Polish). In: Olko, J., Wicherkiewicz, T., Borges, R. (eds.) Integral Strategies for Language Revitalization, 1st edn., pp. 175–200. Faculty of “Artes Liberales”, University of Warsaw, Warsaw (2016). https://culturalcontinuity.al.uw.edu.pl/resource/integral-strategies-for-language-revitalization/
- Shevelov, G.: A Historical Phonology of the Ukrainian Language (Ukrainian translation). Vakulenko, S., Danylenko, A. (trans.), Ushkalov, L. (ed.). Naukove vydavnyctvo “AKTA”, Kharkiv (2002, original work published 1979). http://irbis-nbuv.gov.ua/ulib/item/UKR0001641
- Rieger, J.: Stanovysko i zrižnycjuvanja „rusynskŷx” dialektiv v Karpatax (in Rusyn). In: Magosci, P. (ed.) Najnowsze dzieje języków słowiańskich. Rusynʹskŷj jazŷk, pp. 39–66. 2nd edn. Uniwersytet Opolski — Instytut Filologii Polskiej, Opole (2007). https://www.unipo.sk/cjknm/hlavne-sekcie/urjk/vedecko-vyskumna-cinnost/publikacie/26405/
- Vaňko, J.: Klasifikacija i holovnŷ znakŷ Karpatʹskŷx Rusynʹskŷx dialektiv (in Rusyn). In: Magosci, P. (ed.) Najnowsze dzieje języków słowiańskich. Rusynʹskŷj jazŷk, pp. 67–84. 2nd edn. Uniwersytet Opolski — Instytut Filologii Polskiej, Opole (2007). https://www.unipo.sk/cjknm/hlavne-sekcie/urjk/vedecko-vyskumna-cinnost/publikacie/26405/
- Vaňko, J.: The Rusyn language in Slovakia: between a rock and a hard place. In: Duchêne, A. (ed.) International Journal of the Sociology of Language, vol. 2007, no. 183, pp. 75–96. Walter de Gruyter GmbH, Berlin (2007). https://doi.org/10.1515/IJSL.2007.005
- Sopolyha, M.: Do pytanʹ etničnoï identyfikaciï ta sučasnyx etničnyx procesiv ukraïnciv Prjašivščyny (in Ukrainian). In: Skrypnyk, H. (ed.) Ukraïnci-rusyny: etnolʹinhvistyčni ta etnokulʹturni procesy v istoryčnomu rozvytku, pp. 454–487. National Academy of Sciences of Ukraine, National Association of Ukrainian Studies, Rylsky Institute of Art Studies, Folklore and Ethnology, Kyiv (2013). http://irbis-nbuv.gov.ua/ulib/item/UKR0001502
- Orynycz, P.: Say It Right: AI Neural Machine Translation Empowers New Speakers to Revitalize Lemko. In: Degen, H., Ntoa, S. (eds.) Artificial Intelligence in HCI. HCII 2022. Lecture Notes in Computer Science, vol 13336, pp. 567–580. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-05643-7_37
- Orynycz, P., Dobry, T., Jackson, A., Litzenberg, K.: Yes I Speak… AI neural machine translation in multi-lingual training. In: Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC) 2021, Paper no. 21176. National Training and Simulation Association, Orlando (2021). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?Year=2021&AbID=96953&CID=862
- Scherrer, Y., Rabus, A.: Neural morphosyntactic tagging for Rusyn. In: Mitkov, R., Tait, J., Boguraev, B. (eds.) Natural Language Engineering, vol. 25, no. 5, pp. 633–650. Cambridge University Press, Cambridge (2019). https://doi.org/10.1017/S1351324919000287
- Horoszczak, J.: Słownik łemkowsko-polski, polsko-łemkowski (in Polish). Rutenika, Warsaw (2004).
- Pyrtej, P.: Korotkyj slovnyk lemkivsʹkyx hovirok (in Ukrainian). Siversiya MV, Ivano-Frankivsk (2004).
- Duda, I.: Lemkivsʹkyj slovnyk (in Ukrainian). Aston, Ternopil (2011).
- Rieger, J.: Słownictwo i nazewnictwo łemkowskie (in Polish). Wydawnictwo naukowe Semper, Warsaw (1995).
- Fontański, H., Chomiak, M.: Gramatyka języka łemkowskiego (in Polish). Wydawnictwo Naukowe „Śląsk”, Katowice (2000).
- Pyrtej, P.: Dialekt łemkowski. Fonetyka i morfologia (in Polish). Hojsak, W. (ed.). Zjednoczenie Łemków, Gorlice (2013).
- Post, M.: A Call for Clarity in Reporting BLEU Scores. In: Proceedings of the Third Conference on Machine Translation (WMT), vol. 1, pp. 186–191. Association for Computational Linguistics, Brussels (2018). https://doi.org/10.48550/arXiv.1804.08771
- Papineni, K., Roukos, S., Ward, T., Wei-Jing, Z.: BLEU: a Method for Automatic Evaluation of Machine Translation. In: Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL 02), pp. 311–318. Association for Computational Linguistics, Philadelphia (2002). https://doi.org/10.3115/1073083.1073135
- Snover, M., Dorr, B., Schwartz, R., Micciulla, L., Makhoul, J.: A Study of Translation Edit Rate with Targeted Human Annotation. In: Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, pp. 223–231. Association for Machine Translation in the Americas, Cambridge (2006). https://aclanthology.org/2006.amta-papers.25
- Popović, M.: chrF: character n-gram F-score for automatic MT evaluation. In: Proceedings of the Tenth Workshop on Statistical Machine Translation, pp. 392–395. Association for Computational Linguistics, Lisbon (2015). http://dx.doi.org/10.18653/v1/W15-3049
-

Say It Right: AI Neural Machine Translation Empowers New Speakers To Revitalize Lemko
Abstract
Artificial-intelligence powered neural machine translation might soon resuscitate endangered languages by empowering new speakers to communicate in real time using sentences quantifiably closer to the literary norm than those of native speakers, and starting from day one of their language reclamation journey. While Silicon Valley has been investing enormous resources into neural translation technology capable of superhuman speed and accuracy for the world’s most widely used languages, 98% have been left behind, for want of corpora: neural machine translation models train on millions of words of bilingual text, which simply do not exist for most languages, and cost upwards of a hundred thousand United States dollars per tongue to assemble.
For low-resource languages, there is a more resourceful approach, if not a more effective one: transfer learning, which enables lower-resource languages to benefit from achievements among higher-resource ones. In this experiment, Google’s English-Polish neural translation service was coupled with my classical, rule-based engine to translate from English into the endangered, low-resource, East Slavic language of Lemko. The system achieved a bilingual evaluation understudy (BLEU) quality score of 6.28, several times better than Google Translate’s English to Standard Ukrainian (BLEU 2.17), Russian (BLEU 1.10), and Polish (BLEU 1.70) services. Finally, the fruit of this experiment, the world’s first English to Lemko translation service, was made available at the web address
www.LemkoTran.comto empower new speakers to revitalize their language.New speakers are key to language revitalization, and the power to “say it right” in Lemko is now at their fingertips.
Keywords: Human-Centered AI, Language Revitalization, Lemko.
Please cite as: Orynycz, P. (2022). Say It Right: AI Neural Machine Translation Empowers New Speakers to Revitalize Lemko. In: Degen, H., Ntoa, S. (eds) Artificial Intelligence in HCI. HCII 2022. Lecture Notes in Computer Science(), vol 13336. Springer, Cham. https://doi.org/10.1007/978-3-031-05643-7_37
This version of the contribution has been accepted for publication after peer review but is not the Version of Record and does not reflect post-acceptance improvements, or any corrections. The Version of Record is available online at https://doi.org/10.1007/978-3-031-05643-7_37. Use of this Accepted Version is subject to the publisher’s Accepted Manuscript terms of use: https://www.springernature.com/gp/open-research/policies/accepted-manuscript-terms.
Table of contents
1 Introduction
1.1. Problems
This experiment aims to contribute at the local level to the global challenge of language loss, which may be occurring at the rate of one per day, with as few as one tongue in ten set to survive [1, p. 1329]. At press time, SIL International’s Ethnologue uses Lewis and Simons’ 2010 Expanded Graded Intergenerational Disruption Scale to estimate that 3,018 languages are endangered [2], which is 43% of the 7,001 individual living ones tallied at press time in International Organization for Standardization standard ISO 639-3 [3]. Meanwhile, Google Translate only serves 108 [4], and Facebook, 112 [5], which is a start. Nevertheless, one less language is now underserved, as the fruit of this experiment has been deployed to a web server as a public translation service.
New, artificial intelligence technologies beckon with the promise of an aid that instantly compensates for language loss via human-computer interaction. In my previous experiment, next-generation neural engines achieved higher quality scores translating from Russian and Polish into English than the human control [6, p. 9]. Meanwhile, Facebook and Google1 have invested enormous resources into delivering better-than-human automatic translation systems at zero cost to consumer.
1 Disclosure: I work as a paid Russian, Polish, and Ukrainian linguist and translation quality control specialist for the Google Translate project; headquarters are in San Francisco.
Superhuman artificial intelligence does not come cheap: training neural language models requires bilingual corpora with wordcounts in the hundreds of thousands, and ideally, millions, which would cost hundreds of thousands of dollars to translate, sums beyond the means of most low-resource language communities. Fortunately, this experiment shows that there are more resourceful and effective ways to respond to the challenge of creating translation aids for revitalizing endangered languages in low-resource settings.
1.2 Work So Far
I built the world’s first Lemko to English machine translation system and have made it available to the public. Its objective translation quality scores have been improving: the engine achieved a bilingual evaluation understudy (BLEU) score of 14.57 in the summer of 2021, as presented to professionals at the National Defense Industrial Association’s Interservice/Industry Training, Simulation and Education Conference and published in its proceedings [6]. For reference, I scored BLEU 28.66 as a human translator working in field conditions, cut off from the outside world. By the autumn of 2021, the engine had reached BLEU 15.74, as reported to linguists, academics, and the wider community at an unveiling event hosted by the University of Pittsburgh.2
2 Disclosure: the event was sponsored by the Carpatho-Rusyn Society (Pennsylvania), and I was paid by the University of Pittsburgh for my presentation.
1.3 System Under Study
Lemko is a definitively to severely endangered [6, p. 3, 7, pp. 177-178], low-resource [8], officially recognized minority language [9] presumably indigenous to transborder highlands south of the Cracow, Tarnów, and Rzeszów metropolitan areas; historical demarcating isoglosses will hopefully be the topic of a future paper. Poland’s census bureau tallied 6,279 residents for whom Lemko was a language “usually used at home” (even if in addition to Polish) in 2011 [10, p. 3], a 12% increase from the 5,605 for whom Lemko was a “language spoken most often at home” in 2002 [11, p. 6, 12, p. 7]. At press time, the results of a fresh count are being tabulated.
Lemko is classifiable as an East Slavic language as it fits the customary genetic structural feature criteria, the most significant of which is pleophony [13, p. 20], whereby a vowel is assumed to have arisen in proto-Slavic sequences of consonant
Cfollowed by mid or low vowelV(*e, or*o, with which*ahad merged [14, p. 366]), followed by liquid R (that is,*lor*r), followed by another consonantC, that is,CVRC > CVRVC. To illustrate, compare the Old English word for “melt”, meltan (CVRC) [15, p. 718] to its putative Lemko cognate mołódyj [16, p. 92, 17, p. 150] (CVRC), meaning “young”. Other East Slavic cognates include Ukrainian mołodýj and Russian mołodój [17], both exhibiting a vowel after the liquid (CVRVC). Meanwhile, West Slavic languages lack a vowel before the liquid; compare Polish młody and Slovak mladý (bothCRVC) [17]. Further afield, kinship has been posited for other words translatable as “mild”, including Sanskrit mṛdú (CRC) [18, p. 830] and Latin mollis (CVRCif from *moldvis) [15, 17, 19, p. 323].How well Lemko meets customary, modern Ukrainian genetic structural feature criteria was not evaluated in this experiment. However, similarity between Lemko and Standard Ukrainian was quantified, for the first time in print of which I am aware. Below, my Lemko engine scored BLEU 6.28, nearly three times the score of Google Translate’s Ukrainian at BLEU 2.17. Further experiments could be performed for the purposes of quantification of similarity between Lemko, Standard Ukrainian, Polish, and Rusyn as codified in Slovakia, as well as a fresh take on the typological classification of Lemko.
The quantity and quality of resources have been improving, as has resourcefulness empowered by technology. All known bilingual corpora, comprising fewer than seventy thousand Lemko words, were mustered for this experiment. I have been cleaning a bilingual corpus of transcriptions of interviews conducted with native speakers in Poland and my translations into English, which a United States client paid me to perform and permitted me to use. I am also compiling monolingual corpora, which total 534,512 words at press time.
1.4 Hypothesis
Based on my subjective impression as a professional translator that Lemko native speakers interviewed in Poland were more likely to use words with obvious Polish cognates than Standard Ukrainian ones, I hypothesized that, all else being equal, a machine could be configured to translate into Lemko from English and achieve BLEU objective quality scores higher than those of Google Translate’s Ukrainian and Russian services.
1.5 Predictions
Lemko Translation System. I predicted that the aforementioned translation system would achieve a BLEU score of 15 translating into Lemko from English against the bilingual corpus.
Google Translate.
English to Ukrainian service. I predicted that Google Translate’s English to Ukrainian service would achieve a BLEU score of 10 against the bilingual corpus.
English to Russian service. I predicted that Google Translate’s English to Russian service would achieve a BLEU score of 1 against the bilingual corpus.
1.6 Methods and Justification
In the interest of speed, resource conversation, and ruggedizability, a laptop computer discarded as obsolete by my employer was configured to translate into Lemko and make calls to the Google Cloud Platform Google Translate service, as well as configured to evaluate said translations using the industry standard BLEU metric.
1.7 Principal Results
The English to Lemko translation system achieved a cumulative BLEU score of
6.28431824990417. Meanwhile, Google Translate’s Ukrainian service scored BLEU2.16830846776652, its Russian service BLEU1.10424105952048, and the control of Polish transliterated into the Cyrillic alphabet BLEU1.70036447680114.2 Materials and Methods
The above hypothesis was tested by calculating BLEU quality scores for each translation system set up in the manner detailed below.
2.1 Setup
Hardware. The experiment was conducted on an HP Elitebook 850 G2 laptop with a Core i7-5600U 2.6GHz processor, and 16 gigabytes of random-access memory. It had been discarded by my employer as obsolete and listed for sale at USD 450 at time of press.
Configuration. In the basic input/output system (BIOS) menu, the device was configured to enable Virtualization Technology (VTx).
Operating System. Windows 10 Professional 64 bit had been installed on bare metal. It was ensured that
Virtual Machine PlatformandWindows Subsystem for LinuxWindows features were enabled. Next, theWSL2 Linux kernel update for x64machines (wsl_update_x64.msi) available from Microsoft athttps://aka.ms/wsl2kernelwas installed.Software. The Docker Desktop for Windows version 4.4.3 (73365) installer was downloaded from
https://www.docker.com/get-startedand run with the option toInstall required Windows components for WSL 2 selected.Packages. The experiment depended on the below packages from the Python Package Index.
SacreBLEU. Version 2.0.0 was installed using the Python package documented at the following universal resource locator (URL):
https://pypi.org/project/sacrebleu/2.0.0/Google Cloud Translation API client library. Version 2.0.1 was installed using the Python package documented at the universal resource locator (URL)
https://pypi.org/project/google-cloud-translate/2.0.1/The above dependencies were specified in the requirements file as follows:
google-cloud-translate==2.0.1
sacrebleu==2.0.0Container.
Build. The experiment was run in a Docker container featuring the latest version of the Python programming language, which was version 3.10.2 at the time, running on the Debian Bullseye 11 Linux operating system of AMD64 architecture, of Secure Hash Algorithm 2 shortened digest
bcb158d5ddb6, obtainable via the following command:docker pull python@sha256:bcb158d5ddb636fa3aa567c987e7fcf61113307820d466813527ca90d60fedc7Runtime. The container was configured to save raw experiment data files to a local bind mounted volume.
Translation Quality Scoring.
Translation quality scores were calculated according to the BLEU metric using version 2.0.0 of the SacreBLEU tool invented by Post [20].Case sensitivity. The evaluation was performed in a case-sensitive manner.
Tokenization. Segments were tokenized using version 13a of the Workshop on Statistical Machine Translation standard scoring script metric internal tokenization procedure.
Smoothing Method. The smoothing technique developed at the National Institute of Standards and Technology by United States Federal Government employees for their Multimodal Information Group BLEU toolkit, being the third technique described by Chen and Cherry [21, p. 363], was employed by default.
Signature. The above settings produced the following signature:
nrefs:1|case:mixed|eff:no|tok:13a|smooth:exp|version:2.0.0Calibration. Configured as above, the machine produces the following output:
Segment 1031.English source Everything was there.Lemko reference and transliteration Вшытко там было.Všŷtko tam bŷlo.Lemkotran.comhypothesis and transliterationВшытко там было.Všŷtko tam bŷlo.Score BLEU = 100.00 100.0/100.0/100.0/100.0 (BP = 1.000 ratio = 1.000 hyp_len = 4 ref_len = 4)Explanation. The hypothesis segment was identical to the reference one and the machine achieved a perfect score of BLEU 100.
Segment 179.English source I don't remember what year.Lemko reference and transliteration Не памятам в котрым році.Ne pamjatam v kotrŷm roci.Lemkotran.comhypothesis and transliterationНі памятам, в котрым році.Ni pamjatam, v kotrŷm roci.Score BLEU = 43.47 71.4/50.0/40.0/25.0 (BP = 1.000 ratio = 1.167 hyp_len = 7 ref_len = 6)Explanation. The hypothesis was different from the reference by two characters. The machine mistranslated the particle negating the verb, using the word for “no” (ni) instead of the expected word for “not” (ne). This has since been largely fixed. The machine also added a comma after pamjatam, which means “I remember”. That dropped the score from what would have been a perfect score of 100 to 43.47.
Control. As the corpus is based on interviews conducted in Poland, translations into Polish were used as a control. They were transliterated into the Cyrillic alphabet by reversing the rules for transliterating Lemko names established by Poland’s Ministry of the Interior and Administration [22, p. 6564]. Polish nasal vowels were decomposed into a vowel plus a nasal stop, except before approximants, where they were directly denasalized. Word finally, the front nasal vowel /ę/ was simply denasalized, and the back one /ą/ was transliterated as if followed by a dental stop.
3 Results
The engine available to the public at
www.LemkoTran.comtook first place with a cumulative translation quality score of BLEU 6.28, nearly three times that of the runner-up, Google Translate’s English-Ukrainian service (BLEU 2.17). Next was its English-Polish service (BLEU 1.70), with its English-Russian service in last place (BLEU 1.10).
Table 1. English to Lemko Translation Quality: LemkoTran.com versus Google Translate 3.1 Results by machine translation service
Control. When transliterated into the Cyrillic alphabet, Google Translate’s translations into Standard Polish achieved a corpus-level BLEU score of 1.70. Samples of its performances are as follows:
Segment 2174.English source We had still been in Izby, right.Lemko reference and transliteration То мы іщы были в Ізбах, так.To mŷ iščŷ bŷly v Izbach, tak.Polish hypothesis and transliteration Билісьми єще в Ізбах, так.Byliśmy jeszcze w Izbach, tak.Score BLEU = 46.20Segment 854.English source And that's what it's all about.Lemko reference and transliteration І о то ходит.I o to chodyt.Polish hypothesis and transliteration І о то власьнє ходзі.I o to właśnie chodzi.Score BLEU = 32.47Segment 217.English source And that's what it's all about.Lemko reference and transliteration Так мі повіл.Tak mi povil.Polish hypothesis and transliteration Так мі повєдзял.Tak mi powiedział.Score BLEU = 35.36Hybrid English-Lemko Engine. The engine freely available to the public at the URL
www.LemkoTran.comachieved a corpus-level BLEU score of 6.28.Segment 1031.English source Everything was there.Lemko reference and transliteration Вшытко там было.Všŷtko tam bŷlo.Lemkotran.comhypothesis and transliterationВшытко там было.Všŷtko tam bŷlo.Score BLEU = 100.00Segment 1445.English source But that officer took that medal and said,Lemko reference and transliteration Але тот офіцер взял тот медаль і повідат:Ale tot oficer vzial tot medal' i povidat:Lemkotran.comhypothesis and transliterationАле тот офіцер взял тот медаль і повіл:Ale tot oficer vzial tot medal' i povil:Score BLEU = 75.06Segment 217.English source That's what he said to me.Lemko reference and transliteration Так мі повіл.Tak mi povil.Lemkotran.comhypothesis and transliterationТак мі повіл.Tak mi povil.Score BLEU = 100.00Ukrainian. Google Translate’s translations into Standard Ukrainian achieved a corpus-level BLEU score of 2.35.
Segment 2419.English source Where and when?Lemko reference and transliteration Де і коли?De i koly?Ukrainian hypothesis and transliteration Де і коли?De i koly?Score BLEU = 100.00Segment 1096.English source We were there for three months.Lemko reference and transliteration Там зме были три місяці.Tam zme bŷly try misiaci.Ukrainian hypothesis and transliteration Ми були там три місяці.My buly tam try misjaci.Score BLEU = 30.21Segment 2513.English source Well, here to the west.Lemko reference and transliteration Но то ту на захід.No to tu na zachid.Ukrainian hypothesis and transliteration Ну, тут на захід.Nu, tut na zachid.Score BLEU = 30.21Russian. Google Translate’s English to Russian service achieved a corpus-level BLEU score of 1.10.
Segment 432.English source Nobody knew.Lemko reference and transliteration Нихто не знал.Nychto ne znal.Russian hypothesis and transliteration Никто не знал.Nikto ne znal.Score BLEU = 59.46Segment 2751.English source What did they expel us for?Lemko reference and transliteration За што нас выгнали?Za što nas vŷhnaly?Russian hypothesis and transliteration За что нас выгнали?Za čto nas vygnali?Score BLEU = 42.73Segment 2164.English source Brother went off to war.Lemko reference and transliteration Брат пішол на войну.Brat pišol na vojnu.Russian hypothesis and transliteration Брат ушел на войну.Brat ušel na vojnu.Score BLEU = 42.734 Discussion
The Lemko translation system corpus-level BLEU score of 6.28 indicates that while there is much still to be done, things are on track. The Standard Russian score of BLEU 1.10 indicates that Lemko is less similar to Russian than Polish (BLEU 1.70). Perhaps using pre-revolutionary orthography could boost Russian’s score, but that would be an expensive experiment with little obvious benefit.
The transliterated Standard Polish control similarity score of BLEU 1.70 indicates less interference from the dominant language in Poland than might be expected. It would be interesting to redesign the experiment where a handful of computationally inexpensive and obvious sound correspondences (for example, denasalization of *ę to /ja/ and *ǫ to /u/, retraction of *i to /y/, and change of *g to /h/ [23]) were applied to Polish to see if it then scored higher than Standard Ukrainian.
In summary, Lemko has been synthesized in the lab and the power to produce it placed in the hands of speakers both new and native. After a thorough engine overhaul and glossary ramp-up, the next step is to objectively measure, and if feasible, have speakers subjectively rate, the quality of synthetic Lemko versus that produced by native speakers. The day when new speakers of low-resource languages can use machine translation to start communicating in their language overnight is closer, as is the day the Lemko language joins the ranks of those previously endangered, but now revitalized.
Acknowledgements. I would like to thank my colleague Ming Qian of Peraton Labs for inspiring me to conduct this experiment, and Brian Stensrud of Soar Technology, Inc. for introducing us, as well as his encouragement.
I would also like to thank my friend Corinna Caudill for her encouragement and personal interest in the project, as well as for introducing me to Carpatho-Rusyn Society President Maryann Sivak of the University of Pittsburgh, whom I would like to thank for the opportunity to present my work.
I would also like to thank Maria Silvestri of the John and Helen Timo Foundation for conducting interviews with Lemko native speakers and donating the transcripts and my translations of them to research and development.
I would like to Achim Rabus of the University of Freiburg and Yves Scherrer of the University of Helsinki for their interest in the project and ideas.
I would also like to thank Myhal’ Lŷžečko of the minority-language technology blog InterFyisa for his early interest in the project and community outreach.
I would also like to thank fellow son of Zahoczewie Marko Łyszyk for his interest in the project and community outreach.
Finally, I would like to thank my co-author and Antech Systems Inc. colleague Tom Dobry for his encouragement and guidance.
References
1. ^ Graddol, D.: The future of language. Science, 303(5662), 1329-1331 (2004). https://doi.org/10.1126/science.1096546
2. ^ Eberhard, D. M., Simons, G. F., & Fennig, C. D.: Ethnologue: Languages of the World, SIL International. Twenty-fourth edition. SIL International, Dallas (2021). Online version: How many languages are endangered?, https://www.ethnologue.com/guides/how-many-languages-endangered, last accessed 2022/02/11.
3. ^ ISO 639 Code Tables, https://iso639-3.sil.org/code_tables/639/data, last accessed 2022/02/11.
4. ^ Language support, https://cloud.google.com/translate/docs/languages, last accessed 2022/02/11.
5. ^ Select language, https://m.facebook.com/language.php, last accessed 2022/02/11.
6. ^ ^ Orynycz, P., Dobry, T., Jackson, A., & Litzenberg, K.: Yes I Speak… AI Neural Machine Translation in Multi-Lingual Training. In: Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC) 2021, Paper no. 21176. National Training and Simulation Association, Orlando (2021). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?Year=2021&AbID=96953&CID=862
7. ^ Duć-Fajfer, O.: Literatura a proces rozwoju i rewitalizacja tożsamości językowej na przykładzie literatury łemkowskiej. In: Olko, J., Wicherkiewicz, T., Borges, R. (eds.), Integral Strategies for Language Revitalization, pp. 175–200. First edition. Faculty of „Artes Liberales”, University of Warsaw, Warsaw (2016).
8. ^ Scherrer, Y., Rabus, A.: Neural morphosyntactic tagging for Rusyn. In: Mitkov, R., Tait, J., Boguraev, B. (eds.), Natural Language Engineering, 25(5), 633–650. Cambridge University Press, Cambridge (2019). https://doi.org/10.1017/S1351324919000287
9. ^ Reservations and Declarations for Treaty No.148 – European Charter for Regional or Minority Languages (ETS No. 148), https://www.coe.int/en/web/conventions/full-list?module=declarations-by-treaty&numSte=148&codeNature=1&codePays=POL, last accessed 2022/02/11.
10. ^ Formularz indywidualny, https://stat.gov.pl/download/gfx/portalinformacyjny/pl/defaultstronaopisowa/5781/1/1/nsp_2011_badanie__pelne_wykaz_pytan.pdf, last accessed 2022/02/11.
11. ^ Narodowy Spis Powszechny Ludności i Mieszkań 2002 r. z 20 maja (formularz A) https://stat.gov.pl/gfx/portalinformacyjny/userfiles/_public/spisy_powszechne/nsp2002-form-a.pdf, last accessed 2022/02/11.
12. ^ IV Raport dotyczący sytuacji mniejszości narodowych i etnicznych oraz języka regionalnego w Rzeczypospolitej Polskiej – 2013, http://mniejszosci.narodowe.mswia.gov.pl/download/86/14637/TekstIVRaportu.pdf, last accessed 2022/02/11.
13. ^ Vaňko, J.: The Language of Slovakia’s Rusyns. East European Monographs, New York (2000).
14. ^ Forston, B., IV: Indo-European Language and Culture. Blackwell Publishing, Oxford (2004).
15. ^ ^ Pokorny, J.: Indogermanisches etymologisches Wörterbuch, Bern, 1959.
16. ^ Horoszczak, J.: Słownik łemkowsko-polski, polsko-łemkowski. Rutenika, Warsaw (2004).
17. ^ ^ ^ ^ Vasmer, M. Russisches etymologisches Wörterbuch. Zweiter Band. Carl Winter, Universitätsverlag, Heidelberg (1955).
18. ^ Monier-Williams, M.: A Sanskrit-English Dictionary Etymologically and Philologically Arranged with Special Reference to Cognate Indo-European Languages, The Clarendon Press, Oxford (1899).
19. ^ Derksen, R.: Etymological Dictionary of the Slavic Inherited Lexicon. In: Lubotsky, A. (ed.) Leiden Indo-European Etymological Dictionary Series, vol. 4, Koninklijke Brill, Leiden (2008).
20. ^ Post, M.: A Call for Clarity in Reporting BLEU Scores. In: Proceedings of the Third Conference on Machine Translation (WMT), vol. 1, pp. 186–191. Association for Computational Linguistics, Brussels (2018). https://aclanthology.org/W18-63
21. ^ Chen B., Cherry, C.: A Systematic Comparison of Smoothing Techniques for Sentence-Level BLEU. In: Proceedings of the Ninth Workshop on Statistical Machine Translation, pp. 362–367. Association for Computational Linguistics, Baltimore (2014). http://dx.doi.org/10.3115/v1/W14-33
22. ^ Ministerstwo Spraw Wewnętrznych i Administracji: Rozporządzenie Ministra Spraw Wewnętrznych i Administracji z dnia 30 maja 2005 r. w sprawie sposobu transliteracji imion i nazwisk osób należących do mniejszości narodowych i etnicznych zapisanych w alfabecie innym niż alfabet łaciński. In: Dziennik Ustaw Nr 102, pp. 6560–6573. Rządowe Centrum Legislacji, Warsaw (2005).
23. ^ Shevelov, G.: On the Chronology of H and the New G in Ukrainian. In: Harvard Ukrainian Studies, vol. 1, no. 2, pp. 137–152. Harvard Ukrainian Research Institute, Cambridge (1977). https://www.jstor.org/stable/40999942