Abstrakt
Keď sa strácajú menšinové a lokálne jazyky, trpí národná bezpečnosť: nielenže sa často dokumentuje výrazný nárast samovražednosti, depresie, cukrovky, útokov a zneužívania návykových látok, ale vzniká aj prázdnota, ktorú historicky zneužívali protivníci. Napríklad milióny ľudí z menšinových jazykových komunít si ahistoricky osvojujú ruský jazyk a/alebo identitu ako svoju vlastnú na Ukrajine, v Bielorusku, u spojencov NATO a dokonca aj v Spojených štátoch. Ak komunikačné medzery v rodnom jazyku zostanú len v rukách protivníkov, ktorí využívajú svoje dlhoročné skúsenosti s týmito jazykmi, NATO zostáva vo veľkej nevýhode pri pokusoch o zapojenie týchto komunít. V Európe sa psychické rany spôsobené čiastočne stratou jazyka nezahojili asimiláciou. Namiesto toho mestá zažívajú návaly izolačného napätia na Západe a východné obyvateľstvo je presviedčané nepriateľskými mocnosťami, že tieto mocnosti sú ich skutočnými spojencami, ktorí ich chápu a rešpektujú. Ani vzdelávanie v úradnom jazyku nie je všeliekom: v prípade Ukrajiny (a dokonca aj Španielska) netriviálne rozdiely medzi miestnymi lektmi a úradným jazykom vytvárajú priestor pre protivníkov na rozduchávanie plameňov separatizmu.
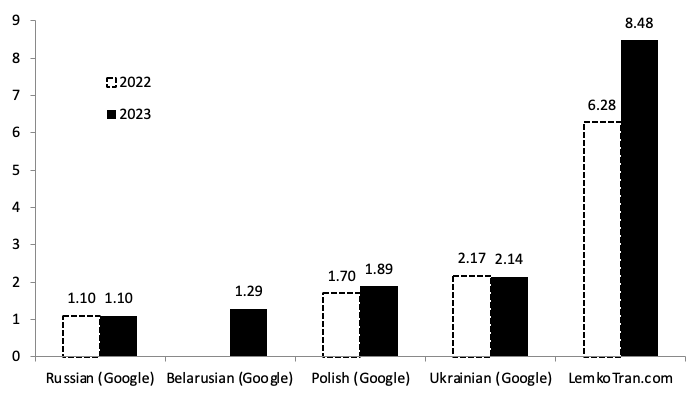
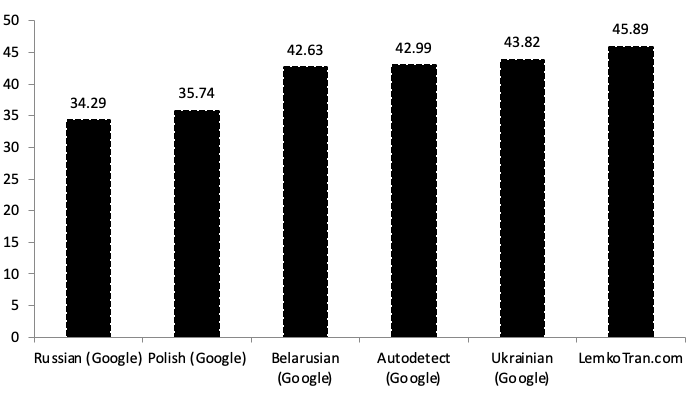
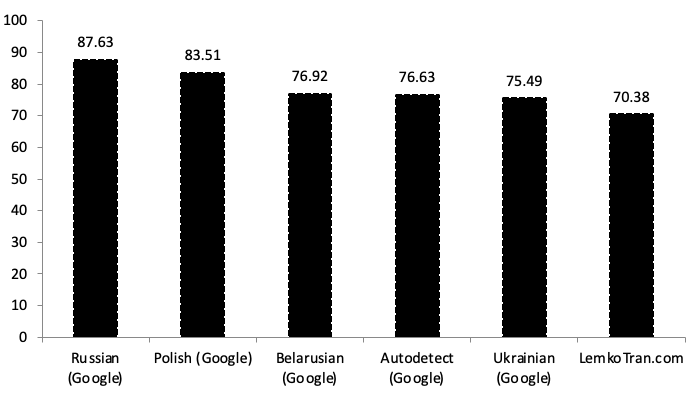
Používanie systémov strojového prekladu na posilnenie NATO a jeho partnerov pri výcviku regrútov alebo pri pôsobení v teréne v jazyku, ktorý je im najbližší, môže okamžite vytvoriť pocit „my“ a predstaviť polykultúrnu víziu NATO. Umelá inteligencia a systémy založené na pravidlách boli zostavené na preklad medzi úradným jazykom Poľska a jazykom jeho pôvodnej lemkovskej menšiny, ktorá bola dlho terčom zahraničných mocností. Systémy boli hodnotené pri preklade z lemkovčiny do poľštiny pomocou metrík vyvinutých s podporou DARPA, pričom dosiahli skóre BLEU (bilingual evaluation understudy) 31,13 a mieru úprav prekladu (TER) 54,10. Medzitým v opačnom smere systémy dosiahli TER 53,73 a BLEU 29,49, čo je skóre 6,5-krát lepšie ako služba Poľsko-ukrajinského prekladača Google Translate.
Please cite as: Orynycz, P., & Dobry, T. (2023). Winning Hearts & Tongues: Prípadová štúdia prekladu z poľštiny do lemkovčiny. V Zborníku z konferencie o výcviku, simulácii a vzdelávaní medzi službami/priemyslom (I/ITSEC).
Please cite as:
Orynycz, P., & Dobry, T. (2023). Winning Hearts & Tongues: A Polish to Lemko Case Study. In Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?AbID=121223&CID=1001
✅ Táto verzia príspevku bola prijatá na publikovanie po recenznom konaní, ale nie je finálnou verziou (Version of Record) a neodráža vylepšenia po prijatí ani žiadne opravy. Finálna verzia (Version of Record) je dostupná online na tomto odkaze. Používanie tejto prijatej verzie podlieha podmienkam používania prijatej rukopisnej verzie vydavateľa.
Úvod
Výsledky školení môžu profitovať z používania strojového prekladu pre pôvodné a menšinové jazyky a dialekty, ktorých používanie je v vedeckej literatúre čoraz viac a významne (p ≤ 0,05) spájané s bystrejšou mysľou, odolnejšou psychikou a pevnejším zdravím, nehovoriac o šesťnásobne nižšej miere samovrážd (Hallett et al., 2007, s. 398). Používanie dedičného jazyka môže posilniť odolnosť voči vplyvu zahraničných protivníkov a v severoatlantickom priestore môže zabrániť cieľovým populáciám, aby upadli do ruskej alebo inej ahistorickej etnolingvistickej identity pri vyrovnávaní sa s ničivými následkami straty jazyka. Zatiaľ čo lokalizácia materiálov do miestnych dialektov a jazykov mohla byť pre vojnou zničené komunity a vlády predtým nedosiahnuteľná, vďaka nedávnym prelomom v oblasti umelej inteligencie a výpočtovej lingvistiky je teraz možné uvažovať o cenovo dostupných zariadeniach, ktoré sú lacnejšie, rýchlejšie a lepšie ako ľudia pri preklade do pôvodných a menšinových jazykov s nízkymi zdrojmi.
Problém straty jazyka sa neobmedzuje len na Európu. Hoci globálna situácia ohrozenia jazykov nemusí byť taká vážna, ako naznačovali dostupné údaje na začiatku deväťdesiatych rokov, dostupné štatistiky stále vykresľujú pochmúrny obraz. V často citovanom diele, ktoré Simmons a Lewis (2013) nazvali „veľkým lingvistickým volaním do zbrane“, Krauss v roku 1992 varoval, že polovica až 90 % svetových jazykov má v tomto storočí zaniknúť. Okrem toho predpokladal „zdokumentovanú mieru zničenia“ 90 % pôvodných jazykov v anglosfére, kde prevláda angličtina, a odhadovanú 50 % mieru vymierania pre celý Sovietsky zväť, kde dominovala ruština (Krauss, 1992, s. 5). O dvadsať rokov neskôr Simmons a Lewis (2013) použili aktualizované údaje na odhad, že 1 360 zo 7 103 živých jazykov (19 %) sa neprenáša na ďalšiu generáciu (s. 12), pričom toto číslo stúpa na 30 % vo východnej Európe (s. 13).
Neuroveda a výsledky učenia
Najnovší výskum naznačuje, že používanie rodného jazyka môže znamenať väčšiu mentálnu kapacitu dostupnú pre učenie a že výsledky testov sa výrazne zlepšujú. Výskum na McGovernovom inštitúte pre výskum mozgu, vedený výskumníkmi z Massachusettského technologického inštitútu (MIT) začiatkom tohto roka, pozoroval relatívne nízku mozgovú odozvu na podnety v rodnom jazyku pri meraní pomocou techniky funkčnej magnetickej rezonancie (fMRI) (Malik-Moraleda et al., 2023). Ako vysvetlenie výskumníci naznačili, že odbornosť znižuje množstvo mozgovej kapacity potrebnej na splnenie úlohy (Mesa, 2023). V nedávnej štúdii pre Svetovú banku Soh, Del Carpio a Wang (2021) zistili, že používanie nerodného vyučovacieho jazyka môže byť škodlivé, a to najmä pre mužov. V štúdii sa výsledky testov z matematiky a prírodných vied u študentov v Malajzii výrazne znížili po tom, čo bol vyučovací jazyk zmenený z malajčiny na angličtinu (Soh et al., 2021, s. 4, 17, 18–19).
Národná bezpečnosť
Podľa členov fakulty Školy špeciálnych operácií Organizácie Severoatlantickej zmluvy (NATO) Whitea a Overdeera môže Rusko zneužívať etnické rozpory v cieľových spoločnostiach ako páku hybridnej vojny v snahe dosiahnuť ciele zahraničnej politiky (2020, s. 31–33), pričom etnolingvistické rozdiely sú „ľahko dostupné a ľahko zhoršiteľné“ (s. 40). Nižšie sa skúma podnecovanie a zneužívanie etnolingvistických konfliktov v západnej aj východnej Európe.
Španielsko: Katalánsko
Verejné používanie katalánčiny, menšinového jazyka hovoreného v severovýchodnom Španielsku, bolo Francovou vládou zakázané až do roku 1975 (Miller & Miller, 1996, s. 113). Namiesto vyriešenia konfliktu táto politika mohla spôsobiť jeho pretrvávanie. V článku pre The New York Times Schwirtz a Bautista (2021) citovali európsku spravodajskú správu z júna 2020, ktorá tvrdila, že elitná Jednotka 29155 vojenského spravodajského systému Ruskej federácie bola v Katalánsku v čase referenda o nezávislosti v roku 2017, keď „tajná protestná skupina“ Tsunami Democràtic obsadila barcelonské letisko a prerušila hlavnú diaľnicu spájajúcu Španielsko s jeho severnými susedmi. O tri dni neskôr plukovník ruskej Federálnej ochrannej služby a blízky príbuzný vysokého prezidentského poradcu, hlboko zapojeného do ruských snáh o podporu separatistov na Ukrajine, prileteli z Moskvy na strategické stretnutie, aby prediskutovali katalánske hnutie za nezávislosť (Schwirtz & Bautista, 2021).
Podpora Ruskej federácie pre katalánske hnutie za nezávislosť údajne zahŕňala dokonca ponuku 10 000 vojakov a 500 miliárd amerických dolárov v prípade nezávislosti (Baquero et al., 2022; pozri tiež Brunet, 2022, s. 74). Louise I. Shelley z Centra pre terorizmus, nadnárodnú kriminalitu a korupciu na George Mason University vo Virgínii označila ruské oslovovanie separatistických lídrov v Španielsku za konzistentné s minulým správaním a vysvetlila: „Väzby medzi Kataláncami a Rusmi siahajú do sovietskej éry. Pred rozpadom ZSSR sa v Barcelone konali stretnutia na vysokej úrovni s významnými Rusmi“ (Baquero et al., 2022).
Západná Ukrajina
Na Ukrajine netriviálne rozdiely medzi miestnymi lektmi a literárnym štandardom vyučovaným v školách vytvárajú priestor pre protivníkov na rozduchávanie plameňov separatizmu. Podľa správy Rating z roku 2012 len 54 % etnických Ukrajincov používalo svoj dedičný jazyk, pričom 29 % používalo ruštinu a 17 % kombináciu oboch (s. 9). V tom roku bolo vytlačených deväť kníh v ruštine na každú jednu v ukrajinčine a len 13 % výtlačkov tlačených médií bolo napísaných v ukrajinčine (Moser, 2016a, s. 604).
Pred dvoma desaťročiami ročné správy Ministerstva zahraničných vecí Spojených štátov amerických o praktikách v oblasti ľudských práv za rok 2002 uviedli nasledovné:
Niektoré proruské organizácie vo východnej časti krajiny sa sťažovali na zvýšené používanie ukrajinčiny v školách a v médiách. Tvrdili, že ich deti boli znevýhodnené pri prijímacích skúškach na vysoké školy, keďže všetci uchádzači museli absolvovať test z ukrajinského jazyka.
Ministerstvo zahraničných vecí, 2003, s. 1758
Rusíni (Ruténi) naďalej žiadali o štatút oficiálnej etnickej skupiny v krajine. Zástupcovia rusínskej komunity žiadali rusínske školy, rusínske oddelenie na Užhorodskej univerzite a zaradenie rusínčiny ako jednej z etnických skupín krajiny do sčítania ľudu v roku 2001. Podľa rusínskych lídrov žije v krajine viac ako 700 000 Rusínov.
Ministerstvo zahraničných vecí, 2003, s. 1759
Ako východiskový bod pre širšie otázky spomenuté Ministerstvom zahraničných vecí, ktoré sú mimo rozsahu tohto článku, bývalý člen Harvardovho ukrajinského výskumného inštitútu Michael Moser vysvetlil:
Rusínov možno pravdepodobne najlepšie opísať ako zvyšky Ruténov/Rusínov, ktorí neboli ochotní pripojiť sa k modernému ukrajinskému národnému a jazykovému hnutiu… pôvodne táto neochota nebola založená na žiadnej rusínskej identite v modernom zmysle, ale vyplývala z rusofilných názorov, že Ruténi/Rusíni/Malorusi patria k jednému nedeliteľnému ruskému národu a nebolo tam miesto pre ukrajinský národ a ukrajinský jazyk.
Moser, 2016b, s. 127
V júni 2007 bola v Moskve prezidentským dekrétom založená „Ruská svetová nadácia“ a začala financovať „krajanov“ na Ukrajine, pričom do marca 2011 poskytla viac ako 1 200 000 amerických dolárov (Moser, 2016a, s. 607).
Stretnutie sa konalo v Ruskom dramatickom divadle v ďalekom západnom meste Mukačevo na Ukrajine 25. októbra 2008 (Wiktorek, 2010, s. 100). Dokonca sa objavili správy o stovke ozbrojených jednotlivcov z iných miest vonku (Ukrajinsʹke nacionalʹne objednannja, 2009; pozri tiež Wiktorek, 2010, s. 100). Nech sa tam stalo čokoľvek, o 20:30 tej noci sa na online platforme rusin.forum24.ru objavilo v ruštine vyhlásenie o „obnovení rusínskej štátnosti“. Medzi svojimi sťažnosťami spomína „nahradenie rusínskeho štátneho jazyka haličskou ukrajinčinou, jazykom poľskej Haliče, severného suseda Rusínov.“ (2-nd Europаn [sic] Сongress Subсarpathion [sic] Rusyns, 2008).
V období pred tým, ako nariadil svojej armáde otvorene napadnúť Ukrajinu s cieľom uskutočniť rozsiahlu „špeciálnu vojenskú operáciu“, venoval prezident Ruskej federácie celý odsek „osudu Podkarpatskej Rusi“ vo svojej eseji O historickej jednote Rusov a Ukrajincov:
Samostatne sa budem venovať osudu Podkarpatskej Rusi, ktorá sa po rozpade Rakúsko-Uhorska ocitla v Československu. Značnú časť miestnych obyvateľov tvorili Rusíni. Hoci sa na to dnes už zriedka spomína, po oslobodení Zakarpatska sovietskymi vojskami kongres pravoslávneho obyvateľstva územia vyhlásil podporu pre začlenenie Podkarpatskej Rusi do Ruskej sovietskej federatívnej socialistickej republiky alebo priamo do Sovietskeho zväzu ako samostatnej, Karpatsko-ruskej republiky.
Putin, 2021
Pri ďalšom incidente v regióne dvaja členovia poľskej krajne pravicovej organizácie Falanga, ktorej členovia pôsobili medzi ruskými separatistami na východnej Ukrajine, v roku 2018 podpálili kultúrne centrum maďarskej pôvodnej etnolingvistickej menšiny v regionálnom hlavnom meste Užhorod tak, že ho poliali benzínom a hodili doň Molotovov koktail (Górzyński, 2018).
Zdravie a bezpečnosť
Samovražednosť
Šesťnásobne vyššia miera samovrážd bola pozorovaná v komunitách, kde menej ako polovica uvádza konverzačné znalosti svojho dedičného jazyka (Hallett et al., 2007, s. 398). Pozitívne je, že miera samovrážd u mladých ľudí klesla na nulu vo všetkých prípadoch okrem jedného, kde väčšina uviedla schopnosť viesť konverzáciu vo svojom dedičnom jazyku (s. 397). V štúdii Pezzie a Hernandeza z roku 2022 mali tí, ktorí nehovorili plynule dedičným jazykom, ale ich rodičia áno (s. 95), najväčšiu pravdepodobnosť samovražedných myšlienok (s. 98). Ako vysvetlenie súvislosti medzi stratou jazyka a samovražednými myšlienkami Pezzia a Hernandez naznačujú „akulturačný stres alebo sociálne vylúčenie“ vyplývajúce z toho, že nedostatok plynulosti v jazyku bráni prijatiu za plnohodnotného člena etnickej skupiny (s. 100).
Depresia
Po kontrole veku, pohlavia, vzdelania, finančnej situácie a príslušnosti k etnickej skupine výskumníci zistili, že skrývanie identity vyhýbaním sa používaniu dedičného jazyka na verejnosti (označované ako vyhýbanie sa jazyku) je štatisticky významným (p = 0,006) prediktorom kategorizácie ako „depresívny“ vďaka dosiahnutiu skóre 5 alebo vyššieho v dotazníku Patient Health Questionnaire 9 od Kroenkeho a Spitzera (Olko et al., 2023, s. 5–6). Ako teoretický mechanizmus výskumníci uviedli etnickú diskrimináciu vyvolávajúcu chronický stres, vedúcu k pretrvávajúcej hyperaktivite osi hypotalamus-hypofýza-nadobličky a výsledným zvýšeným hladinám kortikotropín-uvoľňujúceho faktora a kortizolu, pričom poukázali na prácu Willnera (2017), ako aj Slavicha a Irwina (2014).
Cukrovka
Po úprave o socioekonomické faktory bol diabetes mellitus významne (p = 0,005) menej rozšírený v komunitách so znalosťou pôvodného jazyka (Oster et al., 2014, s. 9).
Užívanie tabaku
Väčšia akulturácia na anglický jazyk bola významne spojená s fajčením u starších ázijsko-amerických adolescentov v New Yorku (Rosario-Sim & O’Connell, 2009). V inej štúdii bolo používanie angličtiny doma spojené s vyššou mierou prevalencie fajčenia u ázijsko-americkej mládeže (p = 0,021), rovnako ako vysoká znalosť angličtiny (p = 0,040) (Chen et al., 1999, s. 325). Medzi hispánskymi dievčatami fajčili tie, ktoré hovorili anglicky so svojimi rodičmi, viac ako tie, ktoré hovorili anglicky aj španielsky so svojimi rodičmi (p < 0,0001), ako aj dievčatá, ktoré hovorili španielsky so svojimi rodičmi (p < 0,01) (Epstein et al., 1998, s. 586).
Užívanie návykových látok a útoky
Podľa Austrálskeho štatistického úradu (2011/2012) bola u aborigénskej mládeže vo veku pätnásť až dvadsaťštyri rokov, ktorá hovorila pôvodným jazykom, menšia pravdepodobnosť užívania nelegálnych látok (16 % oproti 26 %), menšia pravdepodobnosť hlásenia nadmerného pitia alkoholu v predchádzajúcich dvoch týždňoch (18 % oproti 34 %) a menšia pravdepodobnosť, že sa v predchádzajúcom roku stali obeťou fyzického alebo hroziaceho násilia (25 oproti 37 %).
Doterajšie riešenia
Neuronová umelá inteligencia
Prelom v neurónovom strojovom preklade medzinárodného tímu s financovaním od Agentúry pre pokročilé obranné výskumné projekty (DARPA) v rámci projektu Broad Operational Language Translation (BOLT) (Cho et al., 2014), ako aj spoločnosti Google (Sutskever et al., 2014), viedol k vzniku systémov schopných dosahovať kvalitatívne skóre porovnateľné s ľudskými. Trénovanie neurónových systémov si však vyžaduje viac dát, než je bežne dostupných pre jazyky s nízkymi zdrojmi.
Strojový preklad založený na pravidlách
Systémy strojového prekladu založené na pravidlách v minulosti boli všeobecne považované za plytvanie peniazmi (Hajič et al., 2000, s. 7) s pozoruhodnou výnimkou pražského systému RUSLAN financovaného Sovietskym zväzom založenou Radou vzájomnej hospodárskej pomoci (RVHP), ktorý produkoval preklady dokumentácie operačných systémov sálových počítačov z češtiny do ruštiny (s. 7), pričom preklady dvoch z piatich viet boli správne, ďalšie dve z piatich obsahovali len drobné chyby a len jedna z piatich si vyžadovala podstatnú úpravu alebo opätovný preklad (s. 8).
Hlavnými dôvodmi zjavného sklamania v Prahe z výsledkov česko-ruských systémov založených na pravidlách bolo, že samotná úloha bola príliš zložitá a že čeština a ruština nie sú dostatočne blízko príbuzné na to, aby bol takýto prístup životaschopný. K zoznamu by sa mohli pridať nerealistické očakávania a nedostatok objektívnych metrík hodnotenia. Medzitým boli výsledky prekladu z češtiny do slovenčiny a poľštiny, všetkých bližšie príbuzných západoslovanských jazykov, celkom povzbudivé (Hajič et al., 2000, s. 12).
Hybridný neurálny/pravidlový strojový preklad
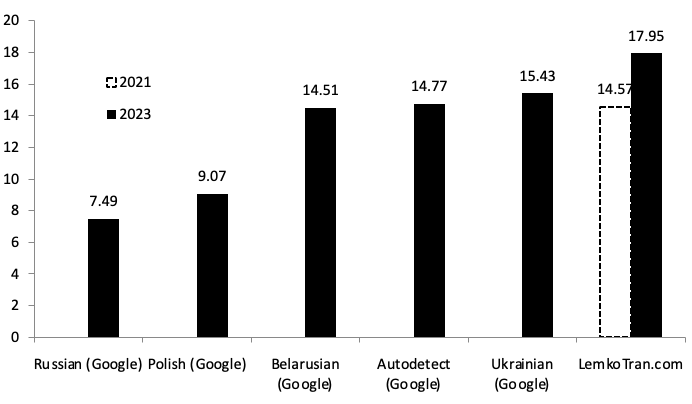
Vo výsledkoch prezentovaných na konferencii Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC) bol pravidlový Lemko-poľský prekladový systém skombinovaný s poľsko-anglickým pravidlovým systémom, aby sa vytvorili prvé publikované výsledky strojového prekladu z Lemko do angličtiny (Orynycz et al., 2021). Nasledujúci rok boli preklady v opačnom smere vytvorené úpravou systému a jeho spustením v opačnom smere (Orynycz, 2022). Vylepšenia tohto systému, ktoré spočívali v jeho prepracovaní a rozšírení slovnej zásoby, neskôr viedli k 35 % zlepšeniu kvality prekladu (Orynycz, 2023).
Nové riešenia
Expertný systém strojového prekladu založený na pravidlách
Inferenčný engine bol ručne kódovaný prostredníctvom vývoja riadeného testami, aby odrážal pravdy obsiahnuté v znalostnej báze zostavenej v spolupráci s prácou odborníkov na danú oblasť. Tento prístup tiež umožňuje manuálne odstránenie cudzieho zasahovania a prečistenie ruských a iných výpožičiek. Konzultované slovníky zahŕňali obojsmerný poľsko-lemkovský slovník Horoszczaka (2004), lemkovsko-ukrajinský slovník Pyrteja (2004), ukrajinsko-lemkovský slovník Dudu (2011) a lemkovsko-poľský glosár Riegera (1995), ako aj jeho lemkovsko-poľský glosár založený na nahrávkach z obce Bartne (2016). Pri kódovaní pravidiel na ohýbanie slov podľa gramatických kategórií, ako sú číslo, pád a rod, boli konzultované gramatiky Fontańského a Chomiaka (2000), ako aj Pyrteja (2013).
Umelá inteligencia Transformer
Prelom v neurálnom strojovom preklade bol úzko nasledovaný zavedením architektúry Transformer vedcami z Google Brain a Google Research, ktorá je založená výlučne na mechanizmoch pozornosti a úplne sa zaobíde bez rekurencie a konvolúcií (Vaswani et al., 2017). Pre tento experiment sme trénovali modely umelej inteligencie založené na transformeroch na preklad z poľštiny do Lemko a pokiaľ vieme, sme prví, ktorí publikovali výsledky.
Materiál a metódy
Materiál
Dáta
Modely umelej inteligencie boli vytvorené pomocou korpusu, ktorý obsahoval 1 611 352 zdrojových slov (podľa počtu v Microsoft Word 365) v 112 507 riadkoch napísaných poľskými rodákmi Lemko, spolu s ich prekladmi do poľštiny pomocou rozhrania Google Cloud Platform Translation Application Programming Interface (API) nakonfigurovaného na preklad, akoby zo štandardnej ukrajinčiny, pomocou neurálneho strojového prekladu.
Lemko (tiež známy ako Lemko Rusyn) geneticky patrí do juhozápadného ukrajinského dialektového systému, v rámci ktorého sa odlišuje pevným prízvukom na predposlednej (predposlednej) slabike (Danylenko, 2020). Takéto dialekty sú pôvodné na územiach, ktoré sú v súčasnosti pod správou Poľska a od roku 1993 aj Slovenskej republiky.
V medzivojnovom Poľsku vláda podporovala samostatné lemkovské, huculské a bojkovské identity v snahe čeliť ukrajinskému hnutiu, ktorého učitelia boli prepustení (Moser, 2016b, s. 128). V roku 1935 boli rusofilní učitelia nahradení Poliakmi a lemkovčina bola v roku 1937 definitívne odstránená zo škôl (s. 128). Asi dve tretiny lemkovských hovoriacich v Poľsku boli deportované na Ukrajinu v rokoch 1945 až 1947, pričom zvyšných 40 000 až 50 000 bolo presídlených predovšetkým na novo pripojené, predtým nemecké územia komunistického Poľska (s. 131). Podľa predbežných výsledkov sčítania ľudu v Poľsku v roku 2021 uviedlo 12 700 „Lemko“ ako etnickú príslušnosť (Główny Urząd Statystyczny, 2023, s. 3).
Metódy
Predspracovanie
Najprv bol všetok text prevedený na malé písmená. Potom bola pridaná medzera pred a za všetky nealfanumerické znaky. Počiatočné a koncové biele znaky boli tiež odstránené z každého riadku. Následne bol vyššie uvedený korpus spracovaný pomocou Moslemovho skriptu (2023a) na čistenie a filtrovanie paralelných dátových súborov (commit db6f441), pričom zostalo 33 612 riadkov obsahujúcich 610 990 zdrojových slov podľa počtu v Microsoft Word 365.
Tokenizácia pod slovami
Modely unigramového podslovného spracovania boli trénované pomocou Moslemovho skriptu (2021a) (commit fbf2488). Následne boli tieto modely použité na tokenizáciu zdrojového aj cieľového textu pomocou skriptu podslovného spracovania číslo dva z rovnakého commitu (Moslem, 2021b).
Rozdelenie dát
2 000 riadkov z vyššie uvedeného korpusu bolo oddelených na vyhodnotenie pomocou Moslemovho skriptu (2023b) na tento účel (commit e6decb7).
Tréning modelov umelej inteligencie
Modely umelej inteligencie boli trénované pomocou verzie TensorFlow nástroja OpenNMT pre neurálny strojový preklad, ktorý je nástupcom Harvardovho modelu seq2seq-attn sekvencia-na-sekvenciu s pozornosťou (Klein et al., 2017, s. 68). Príkaz na spustenie tréningovej a evaluačnej slučky bol spustený s automatickou konfiguráciou pre model Transformer. Automatické vyhodnocovanie bolo tiež povolené a nastavené na spustenie každých 5 000 krokov pomocou metriky BLEU (bilingual evaluation understudy) a export modelu, keď bolo dosiahnuté nové vysoké skóre. Tréning bol vykonaný na platforme Google Colabatory s využitím grafických procesorových jednotiek NVIDIA A100 a stavu runtime s vysokou pamäťou RAM. Tréningu bolo umožnené bežať cez noc.
Inferenčný engine
Inferenčný engine pre preklad bol vytvorený na základe Kleinovho klientskeho skriptu Python (commit 2b196ff) (2021), ktorý bol upravený tak, aby vyhovoval modelom tokenizácie podslov zdrojového a cieľového jazyka, ako aj optimalizoval medzery a kapitalizáciu, aby lepšie zodpovedal očakávaniam modelov umelej inteligencie a koncových používateľov. Predpovede prekladu boli uložené do súboru pre následné hodnotenie kvality.
Hodnotenie kvality
Kvalita prekladov bola hodnotená pomocou metrík, ktorých vývoj bol financovaný DARPA: BLEU (Papineni et al., 2002) aj TER (Translation Edit Rate) (Snover et al., 2006). Samotné skóre bolo vypočítané pomocou priemyselne štandardných metód vyvinutých v Amazon Research spoločnosťou Post (2018).
Výsledky
Skóre kvality prekladu
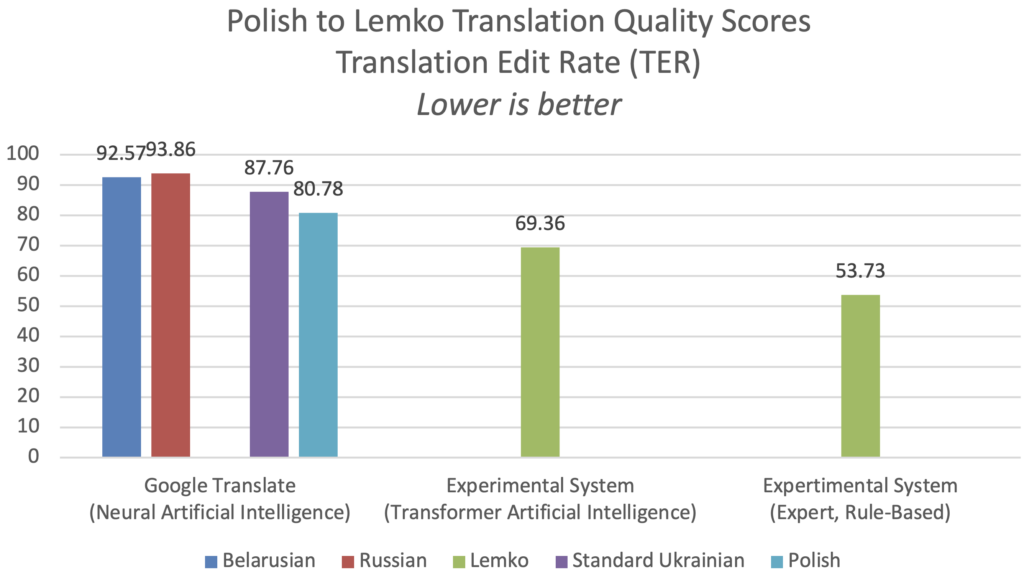
Experimentálny expertný systém založený na pravidlách prekonal všetky ostatné vo všetkých metrikách pri preklade z poľštiny do Lemko a naopak.
Kvalita prekladu z poľštiny do Lemko
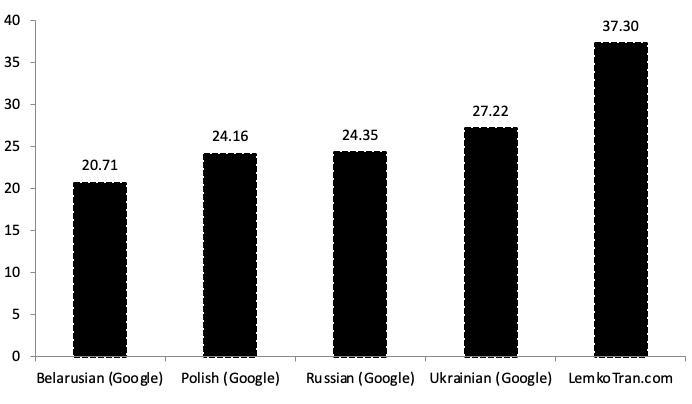
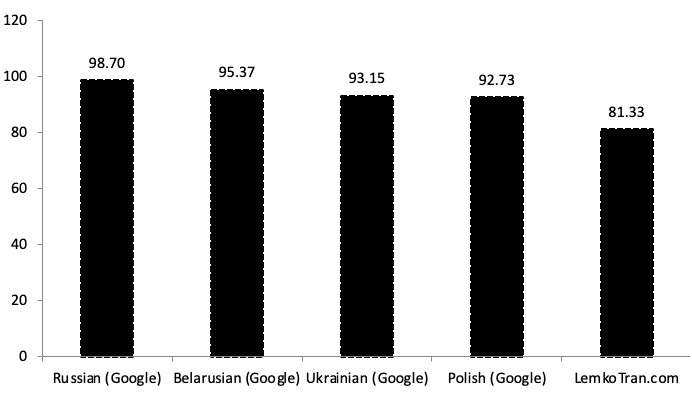
Pri preklade z poľštiny do Lemko dosiahol experimentálny expertný systém založený na pravidlách skóre kvality BLEU 29,49, čo je 6,50-krát lepšie ako ukrajinská služba Google Translate. Medzitým experimentálny systém neurálneho strojového prekladu Transformer s umelou inteligenciou dosiahol skóre BLEU 15,90 po 30 000 tréningových krokoch, čo bolo 3,50-krát lepšie ako ukrajinská služba Google Translate. Pri meraní pomocou alternatívnej metriky TER dosiahol experimentálny expertný systém založený na pravidlách skóre TER 53,73, čo je o 61 % lepšie ako ukrajinská služba Google Translate.

Kvalita prekladu z Lemko do poľštiny
Experimentálny expertný systém založený na pravidlách prekonal všetky ostatné vo všetkých metrikách pri preklade z Lemko do poľštiny, pričom dosiahol skóre kvality BLEU 31,13, čo bolo 1,4-krát lepšie ako výkon ukrajinskej služby Google Translate s BLEU 22,16.
Vzorky
| Anglický význam (ľudský prekladateľ) | Napríklad v textoch, a ja hlavne študujem texty, mám tento zdroj, napísali: Rakúšania nás vraždili, tak čo nám urobia tí strašní Moskovčania, ktorými sa nás snažia vystrašiť? | |||||
| Poľština (ľudský prekladateľ) | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | |||||
| Pravda: Odkaz na Lemko (rodený hovorca) | І они наприклад в текстах, а я головні досліджам тексты, то значыт мам такє джерело, писали: но Австриякы нас мордували, то што зроблят тоты страшны Москалі, котрыма нас страшат? | I ony napryklad v tekstach, a ja holovni dosljidžam tekstŷ, to značŷt mam takie džerelo, pysaly: no Avstryjakŷ nas morduvaly, to što zrobljat totŷ strašnŷ Moskalji, kotrŷma nas strašat? | ||||
| Systém | Prekladové hypotézy | Skóre kvality | ||||
| Cyrilika | Transliterácia | BLEU | TER | |||
| Experimentálne | Expertný systém (založený na pravidlách) | Наприклад они в текстах, а я головні бадам текстий, мам такы джерело, писали: Австриякы нас мордували, то што зроблят тоты страшны москале, котрыма нас страшом? | Napryklad ony v tekstach, a ja holovni badam tekstyj, mam takŷ džerelo, pysaly: Avstryjakŷ nas morduvaly, to što zrobljat totŷ strašnŷ moskale, kotrŷma nas strašom? | 46.32 | 34.48 | |
| Umelá inteligencia (Transformer) | Примірово, в текстах, а я головні в заміріню тексту, маме джерело, писали: австриякы австриякы мордували, же то што зроблят стабілізацию тому, котрыма нас престрашыли? | Prymirovo, v textax, a ja holovni v zamirinju tekstu, mame džerelo, pysaly: avstryjakŷ avstryjakŷ morduvaly, že to što zrobljat stabilyzacyju tomu, kotrŷma nas prestrašŷly? | 27.65 | 55.17 | ||
| Google Translate | Poľština | На прзиклад оні в текстах, а я ґлувнє бадам тексти, мам такє зьрудло, пісалі: Аустряци нас мордовалі, то цо зробьон ці страшні Москалє, ктуримі нас страшон? | Na przyklad oni v tekstach, a ja gluvnje badam teksty, mam takje źrudlo, pisalji: Austriacy nas mordovalji, to co zrobjon ci strašni Moskalje, kturymi nas strašon? | 14.21 | 68.97 | |
| Ukrajinčina | Наприклад, у своїх текстах, а я в основному досліджую тексти, у мене є таке джерело, вони писали: Австрійці нас повбивали, що будуть робити ті страшні москалі, якими вони нам погрожують? | Napryklad, u svojix tekstax, a ja v osnovnomu doslidžuju teksty, u mene je take džerelo, vony pysaly: Avstrijci nas povbyvaly, ščo budutʹ robyty ti strašni moskali, jakymy vony nam pohrožujutʹ? | 9.43 | 82.76 | ||
| Ruština | Например, в их текстах, а я в основном исследую тексты, у меня есть такой источник, они писали: Нас убили австрийцы, что будут делать те страшные москвичи, которыми они нам угрожают? | Naprimer, v ix tekstax, a ja v osnovnom issleduju teksty, u menja estʹ takoj istočnik, oni pisali: Nas ubili avstrijcy, čto budut delatʹ te strašnye moskviči, kotorymi oni nam ugrožajut? | 9.43 | 86.21 | ||
| Bieloruština | Напрыклад, у сваіх тэкстах, а я ў асноўным тэксты дасьледую, у мяне ёсьць такая крыніца, яны пісалі: Аўстрыйцы нас забілі, што будуць рабіць тыя страшныя маскалі, якімі яны нам пагражаюць? | Napryklad, u svaix tèkstax, a ja ŭ asnoŭnym tèksty das′leduju, u mjane ës′c′ takaja krynica, jany pisali: Aŭstryjcy nas zabili, što buduc′ rabic′ tyja strašnyja maskali, jakimi jany nam pahražajuc′? | 4.99 | 96.55 | ||
Diskusia
Dôsledky pre politiku
Výsledky vzdelávania, verejného zdravia a bezpečnosti sa môžu zlepšiť, ak sa vzdelávacie, školiace, komunitné a iné materiály lokalizujú do regionálnych dialektov a jazykov okrem národných štandardných. Aby sa predišlo preťaženiu kapacít ľudských zdrojov, lingvisti by mohli byť poverení post-editovaním výstupu expertných a umelých inteligentných systémov strojového prekladu, namiesto ručného prekladu. Cenovo dostupnejší prístup k preloženým materiálom by mohol priniesť zlepšenie sociálnych služieb v nedostatočne obsluhovaných oblastiach. Stonewall et al. uvádzajú viacjazyčnosť, a tým aj inkluzívnosť, vysoko na svojom zozname osvedčených postupov pre zapojenie nedostatočne obsluhovaných populácií (2017). Európska únia financuje výskum, ktorý naznačuje, že strojový preklad možno použiť na uľahčenie občianskej participácie, ako aj na posilnenie verejného zdravia a bezpečnosti medzi nedostatočne obsluhovanými komunitami (Nurminen & Koponen, 2020).
Technologické dôsledky
Veci sú na dobrej ceste k tomu, aby sa komerčne životaschopný strojový preklad do Lemko stlačením tlačidla stal realitou. Pokračujúci vývoj expertných systémov založených na pravidlách, riadený testami, sa zdá byť najrýchlejšou cestou k nadľudským skóre kvality prekladu. Systémy umelej inteligencie založené na transformeroch môžu zvíťaziť z dlhodobého hľadiska.
Niektoré úpravy postupu tréningu umelej inteligencie si zaslúžia experimentovanie. Skript na filtrovanie korpusu mohol byť pre túto úlohu príliš horlivý a nadmerne zmenšil veľkosť korpusu, čo bránilo výkonu. Skript by mohol byť v budúcom experimente vynechaný. Preučenie môže brániť skóre a možno by sa mal skrátiť interval hodnotenia 5 000 krokov. Použitie expertného systému založeného na pravidlách na preklad korpusov do poľštiny z Lemko namiesto služby Google Cloud Platform by mohlo viesť k lepším výsledkom. Začlenenie modulov automatickej korekcie pravopisu by tiež mohlo globálne zlepšiť skóre.
Ruské a iné cudzie lingvistické zásahy by sa mohli programovo potlačiť prečistením výpožičiek pomocou algoritmov nájdi-nahraď. Národné jazykové akadémie a iné autority by mohli takéto schopnosti považovať za užitočné. Je možné, že kvalita prekladu už dosiahla nadľudské úrovne, čo je hypotéza, ktorú by bolo možné otestovať v budúcich experimentoch.
Vyhlásenie o konfliktných záujmoch
Hlavný autor pôsobí ako špecialista na kontrolu kvality pre projekt Google Translate v San Franciscu.
Referencie
2. Európsky [sic] kongres podkarpatských [sic] Rusínov [rusín]. (2008, 25. október). MEMORANDUM 2-go Evropejskogo Kongressa Podkarpatskix Rusinov o prinjatii AKTA PROVOZGLAŠENIJA vosstanovlenija rusinskoj gosudarstvennosti [Memorandum Druhého európskeho kongresu podkarpatských Rusínov o prijatí vyhlásenia o obnove rusínskej štátnosti] [Online príspevok na fóre]. Informacionnoe Agenstvo Podkarpatskoj Rusi. IAPR. Forum podkarpatskix rusinov.
http://rusin.forum24.ru/?1-9-0-00000005-000-0-0-1224955832
Austrálsky štatistický úrad, (2012). Kultúra, dedičstvo a voľný čas: Hovorenie aborigénskymi a ostrovnými jazykmi Torres Strait. Blahobyt aborigénskych a ostrovných obyvateľov Torres Strait: Zameranie na deti a mládež. (Pôvodné dielo publikované v roku 2011) Získané 1. mája 2023 z https://www.abs.gov.au/ausstats/abs@.nsf/Latestproducts/1E6BE19175C1F8C3CA257A0600229ADC
Baquero, A., Hall, K.G., Tsogoeva, A., Albalat, J.G., Grozev, C., Bagnoli, L., IStories, & Vergine, S. (2022, 8. máj). Podnecovanie odtrhnutia, sľubovanie bitcoinov: Ako ruský operátor nabádal katalánskych lídrov k rozchodu s Madridom. Projekt pre organizovaný zločin a korupciu (OCCRP). https://www.occrp.org/en/investigations/fueling-secession-promising-bitcoins-how-a-russian-operator-urged-catalonian-leaders-to-break-with-madrid
Brunet, F. (2022). Ekonomika katalánskeho separatizmu. Cham: Springer Nature Switzerland AG. https://doi.org/10.1007/978-3-031-14451-6
Chen, X., Unger, J.B., Cruz, T.B., & Johnson, C.A. (1999). Fajčiarske návyky ázijsko-americkej mládeže v Kalifornii a ich vzťah k akulturácii. Journal of Adolescent Health, 24(5), 321-328. https://doi.org/10.1016/S1054-139X(98)00118-9
Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Učenie reprezentácií fráz pomocou RNN Encoder–Decoder pre štatistický strojový preklad. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), 1724–1734 http://dx.doi.org/10.3115/v1/D14-1179
Danylenko, A. (2020). „Carpatho-Rusyn“, in: Encyclopedia of Slavic Languages and Linguistics Online, hlavný redaktor Marc L. Greenberg. Konzultované online 13. júna 2023
http://dx.doi.org/10.1163/2589-6229_ESLO_COM_031960
Ministerstvo zahraničných vecí (2003). S.Prt. 108-30, Zväzok I – SPRÁVY O PRAXI V OBLASTI ĽUDSKÝCH PRÁV ZA ROK 2002 ZVÄZOK I. Washington, D.C: U.S. Government Publishing Office. https://www.govinfo.gov/app/details/CPRT-108JPRT86917/CPRT-108JPRT86917
Duda, I. (2011). Lemkivsʹkyj slovnyk [Lemkovský slovník]. Ternopil: Aston.
Epstein, J. A., Botvin, G.J., & Diaz, T. (1998). Lingvistická akulturácia a rodové vplyvy na fajčenie u hispánskej mládeže. Preventívna medicína, 27(4), 583–589. https://doi.org/10.1006/pmed.1998.0329
Fontański, H., & Chomiak, M. (2000). Gramatyka języka łemkowskiego [Gramatika lemkovského jazyka]. Katowice: „Śląsk” Sp. z o.o. Wydawnictwo Naukowe.
Główny Urząd Statystyczny (2023). Wstępne wyniki NSP 2021 w zakresie struktury narodowo-etnicznej oraz języka kontaktów domowych [Predbežné výsledky sčítania ľudu 2021 v oblasti národnostnej a etnickej štruktúry a jazyka používaného v domácnosti]. Získané 11. júna 2023 z https://stat.gov.pl/spisy-powszechne/nsp-2021/nsp-2021-wyniki-wstepne/wstepne-wyniki-narodowego-spisu-powszechnego-ludnosci-i-mieszkan-2021-w-zakresie-struktury-narodowo-etnicznej-oraz-jezyka-kontaktow-domowych,10,1.html
Górzyński, O. (2018, 3. marec). Tajná kampaň Ruska na podnecovanie východnej Európy. The Daily Beast. https://www.thedailybeast.com/russias-covert-campaign-inflaming-east-europe
Hajič, J., Hric, J., & Kuboň, V. (2000, apríl). Strojový preklad veľmi blízkych jazykov. In Sixth Applied Natural Language Processing Conference (s. 7–12). http://dx.doi.org/10.3115/974147.974149
Hallett, D., Chandler, M.J., & Lalonde C.E. (2007): Znalosť pôvodných jazykov a samovraždy mládeže. Kognitívny vývoj. 22(3), 392–399. https://doi.org/10.1016/j.cogdev.2007.02.001
Horoszczak, J. (2004). Słownik łemkowsko-polski, polsko-łemkowski [Lemkovsko-poľský a poľsko-lemkovský slovník], Varšava: Rutenika.
Klein, G. (2021). Odvodzovanie s TensorFlow Serving. Získané 5. júna 2023, z https://github.com/OpenNMT/OpenNMT-tf/blob/master/examples/serving/tensorflow_serving/ende_client.py
Klein, G., Kim, Y., Deng, Y., Senellart, J., & Rush, A.M. (2017). OpenNMT: Otvorený nástroj pre neurónový strojový preklad. In Zborník príspevkov z 55. výročného stretnutia Asociácie pre počítačovú lingvistiku – Systémové demonštrácie, str. 67–72. https://doi.org/10.18653/v1/P17-4012
Krauss, M. (1992). Svetové jazyky v kríze. Jazyk, 68(1), 4–11. https://doi.org/10.1353/lan.1992.0075
Malik-Moraleda, S., Jouravlev, O., Mineroff, Z., Cucu, T., Taliaferro, M., Mahowald, K., Blank, I., & Fedorenko, E. Funkčná charakterizácia jazykovej siete polyglotov a hyperpolyglotov pomocou presného fMRI. Laboratórium Cold Spring Harbor. Predbežná online publikácia. https://doi.org/10.1101/2023.01.19.524657
Mesa, N. (2023, 3. februára). Váš rodný jazyk má vo vašom mozgu špeciálne miesto, aj keď hovoríte 10 jazykmi. Science, https://doi.org/10.1126/science.adh0055
Miller, H., & Miller, K. (1996). Jazyková politika a identita: prípad Katalánska. Medzinárodné štúdie v sociológii vzdelávania, 6(1). https://doi.org/10.1080/0962021960060106
Moser, M. (2016a). Jazyková politika v súčasnej Ukrajine (25. februára 2010 – 25. februára 2011). In Nové príspevky k histórii ukrajinského jazyka (str. 601–619). Canadian Institute of Ukrainian Studies Press. https://www.ciuspress.com/product/new-contributions-to-the-history-of-the-ukrainian-language/
Moser, M. (2016b). Rusínčina: Nový–starý jazyk medzi národmi a štátmi. In: Tomasz Kamusella, Motoki Nomachi, Catherine Gibson (Eds.), Palgrave Handbook slovanských jazykov, identít a hraníc, 124–139. https://doi.org/10.1007/978-1-137-34839-5_7
Moslem, Y. (2021a). Trénovanie modelov SentencePiece pre zdroj a cieľ. Získané 4. júna 2023, z https://github.com/ymoslem/MT-Preparation/blob/main/subwording/1-train_unigram.py
Moslem, Y. (2021b). Rozdelenie zdrojových a cieľových súborov na podslová. Získané 4. júna 2023, z https://github.com/ymoslem/MT-Preparation/blob/main/subwording/2-subword.py
Moslem, Y. (2023a). Filtrovanie/čistenie paralelných dátových súborov pre strojový preklad. Získané 4. júna 2023, z https://github.com/ymoslem/MT-Preparation/blob/main/filtering/filter.py
Moslem, Y. (2023b). Rozdelenie paralelného dátového súboru na trénovacie, vývojové a testovacie dátové súbory pre strojový preklad. Získané 4. júna 2023, z
https://github.com/ymoslem/MT-Preparation/blob/main/train_dev_split/train_dev_test_split.py
Nurminen, M., & Koponen, M. (2020). Strojový preklad a spravodlivý prístup k informáciám. Prekladateľské priestory, 9(1), 150–169. https://doi.org/10.1075/ts.00025.nur
Olko, J., Galbarczyk, A., Maryniak, J., Krzych-Miłkowska, K., Iglesias Tepec, H, de la Cruz, E., Dexter-Sobkowiak, E., & Jasienska, G. (2023): Špirála znevýhodnenia: Etnolingvistická diskriminácia, akulturačný stres a zdravie v domorodých komunitách Nahua v Mexiku. Americký časopis biologickej antropológie, 1–15. https://doi.org/10.1002/ajpa.24745
Orynycz, P. (2022, máj). Say It Right: Neurónový strojový preklad s umelou inteligenciou posilňuje nových hovoriacich pri revitalizácii Lemko. In Umelá inteligencia v HCI: 3. medzinárodná konferencia, AI-HCI 2022, konaná ako súčasť 24. medzinárodnej konferencie HCI, HCII 2022, virtuálne podujatie, 26. júna – 1. júla 2022, Zborník (str. 567–580). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-031-05643-7_37
Orynycz, P. (2023, júl). BLEU Skies pre revitalizáciu ohrozených jazykov: Presnosť neurónového AI prekladu Lemko Rusyn and Ukrainian stúpa. In Medzinárodná konferencia o interakcii človeka s počítačom (str. 135–149). Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-35894-4_10
Orynycz, P., Dobry, T., Jackson, A., & Litzenberg, K. (2021). Áno, hovorím… Neurónový strojový preklad s umelou inteligenciou vo viacjazyčnom tréningu. In Zborník príspevkov z konferencie Interservice/Industry Training, Simulation, and Education (I/ITSEC). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?Year=2021&AbID=96953&CID=862
Oster, R.T., Grier, A., Lightning, R., Mayan, M.J., & Toth, E.L. (2014). Kultúrna kontinuita, tradičný domorodý jazyk a diabetes u Prvých národov v Alberte: štúdia zmiešaných metód. Medzinárodný časopis pre rovnosť v zdraví, 13(92), 1–11. https://doi.org/10.1186/s12939-014-0092-4
Papineni, K., Roukos, S., Ward, T., & Zhu, W.J. (2002, júl). BLEU: metóda pre automatické hodnotenie strojového prekladu. In Zborník príspevkov zo 40. výročného stretnutia Asociácie pre počítačovú lingvistiku (str. 311–318). https://doi.org/10.3115/1073083.1073135
Pezzia, C., & Hernandez, L.M. (2022). Samovražedné myšlienky v etnicky zmiešanej, vysokohorskej guatemalskej komunite. Transkultúrna psychiatria. 59(1), 93–105. https://doi.org/10.1177/1363461520976930
Post, M. (2018). Výzva na jasnosť pri vykazovaní skóre BLEU. In Zborník príspevkov z Tretej konferencie o strojovom preklade: Výskumné práce, str. 186–191. Brusel: Asociácia pre počítačovú lingvistiku http://dx.doi.org/10.18653/v1/W18-6319
Putin, V. Ob istoričeskom edinstve russkix i ukraincev [O historickej jednote Rusov a Ukrajincov]. Získané 15. mája 2023 z http://kremlin.ru/events/president/news/66181
Pyrtej, P. (2004). Korotkyj slovnyk lemkivsʹkyx hovirok [Stručný slovník lemkovských nárečí]. Ivano-Frankivsk: Siversija MB.
Pyrtej, P. (2013). Lemkivsʹki hovirky. Fonetyka i morfolohija [Lemkovské nárečia. Fonetika a morfológia]. Gorlice: Zjednoczenie Łemków.
Rating, (2012). Pytannja movy: rezulʹtaty ostannix doslidženʹ 2012 roku [Jazyková otázka: Výsledky najnovšieho výskumu v roku 2012]. Získané 26. augusta 2023 z https://ratinggroup.ua/files/ratinggroup/reg_files/rg_mova_dynamika_052012.pdf
Rieger, J. (1995). Słownictwo i nazewnictwo łemkowskie [Lemkovská slovná zásoba a nomenklatúra]. Varšava: Wydawnictwo Naukowe Semper.
Rieger, J. (2016). Mały słownik łemkowkiej wsi Bartne [Malý slovník lemkovskej dediny Bartne]. Varšava: Wydawnictwo Uniwersytetu Warszawskiego.
Rosario-Sim, M.G., & O’Connell K.A. (2009). Depresia a jazyková akulturácia korelujú s fajčením medzi staršími ázijsko-americkými adolescentmi v New Yorku. Ošetrovateľstvo vo verejnom zdravotníctve 26(6), 532–542. https://doi.org/10.1111/j.1525-1446.2009.00811.x
Schwirtz, M., & Bautista, J. (2023, 23. septembra) Zosobášení špióni Kremľa, tieňová misia do Moskvy a nepokoje v Katalánsku. The New York Times. Získané 16. mája 2023 z https://www.nytimes.com/2021/09/03/world/europe/spain-catalonia-russia.html
Simmons, G.F., & Lewis, M.P. (2013). Svetové jazyky v kríze: 20-ročná aktualizácia. In E. Mihas, B. Perley, G. Rei-Doval & K. Wheatley (Eds.), Odpovede na ohrozenie jazykov: Na počesť Mickeyho Noonana. Nové smery v dokumentácii a revitalizácii jazykov (str. 3–20). John Benjamins Publishing Company. https://doi.org/10.1075/slcs.142.01sim
Slavich, G.M., & Irwin, M.R. (2014). Od stresu k zápalu a závažnej depresívnej poruche: teória sociálnej signalizačnej transdukcie depresie. Psychologický bulletin, 140(3), 774–815. https://doi.org/10.1037/a0035302
Snover, M., Dorr, B., Schwartz, R., Micciulla, L., & Makhoul, J. (2006). Štúdia miery úprav prekladu s cielenou ľudskou anotáciou. In Zborník príspevkov zo 7. konferencie Asociácie pre strojový preklad v Amerike: Technické práce, (str. 223–231). https://aclanthology.org/2006.amta-papers.25
Soh, Y.C., Del Carpio, X.V., & Wang, L.C. (2021). Vplyv vyučovacieho jazyka v školách na študijné výsledky: Dôkazy z Malajzie s použitím metódy syntetickej kontroly. Pracovný dokument o politickom výskume skupiny Svetovej banky 9517. http://hdl.handle.net/10986/35031
Stonewall, J., Fjelstad, K., Dorneich, M., Shenk, L., Krejci, C., & Passe, U. (2017, september). Osvedčené postupy pre zapojenie nedostatočne obsluhovaných populácií. In Zborník príspevkov z výročného stretnutia Spoločnosti pre ľudské faktory a ergonómiu (vol. 61, No. 1, str. 130–134). Sage CA: Los Angeles, CA: SAGE Publications. https://doi.org/10.1177/1541931213601516
Sutskever, I., Vinyals, O., & Le, Q.V. (2014). Učenie sekvencie na sekvenciu s neurónovými sieťami. Pokroky v systémoch spracovania neurónových informácií 27 (NIPS 2014). https://proceedings.neurips.cc/paper_files/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html
Ukrajinsʹke nacionalʹne objednannja (2009). Zakarpatsʹke UNO obicjaje vlasnymy sylamy protydijaty separatystam [Zakarpatská ukrajinská národná organizácia sľubuje, že 1. mája vlastnými silami zasiahne proti separatistom] Získané 10. júna 2023, z https://zaxid.net/zakarpatske_uno_obitsyaye_vlasnimi_silami_protidiyati_separatistam_1_travnya_n1076607
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., & Polosukhin, I. (2017). Pozornosť je všetko, čo potrebujete. NIPS’17: Zborník príspevkov z 31. medzinárodnej konferencie o systémoch spracovania neurónových informácií, 6000–6010. https://dl.acm.org/doi/10.5555/3295222.3295349
White, D.J., & Overdeer, D. (2020). Využívanie etnickej príslušnosti v ruských hybridných hrozbách. Strategos: Vedecký časopis Chorvátskej obrannej akadémie 4(1), 31–49. https://hrcak.srce.hr/242087
Wiktorek, A.C. (2010). Rusíni Karpát: Konkurenčné agendy identity. Washington, D.C.: Georgetown University. https://repository.library.georgetown.edu/handle/10822/552816
Willner, P. (2017). Model chronického mierneho stresu (CMS) depresie: História, hodnotenie a použitie. Neurobiológia stresu, 6, 78–93. https://doi.org/10.1016/j.ynstr.2016.08.002