
Absztrakt
Amikor a kisebbségi és helyi nyelvek elvesznek, a nemzetbiztonság szenved: nemcsak az öngyilkossági arány, a depresszió, a cukorbetegség, a támadások és a kábítószer-fogyasztás jelentős növekedését dokumentálják gyakran, hanem egy űrt is teremt, amelyet történelmileg kihasználtak az ellenfelek. Például kisebbségi nyelvi közösségekből származó milliók történelmietlenül sajátjuknak tekintik az orosz nyelvet és/vagy identitást Ukrajnában, Fehéroroszországban, NATO-szövetséges országokban, sőt még az Egyesült Államokban is. Ha az anyanyelvi kommunikációs hiányosságok kizárólag az ellenfelek kezében maradnak, akik kihasználják az ezen nyelvekkel kapcsolatos hosszú tapasztalatukat, a NATO jelentős hátrányban marad, amikor megpróbálja bevonni ezeket a közösségeket. Európában a nyelvi veszteség által részben okozott lelki sebek nem gyógyultak be az asszimilációval. Ehelyett a városok elszigetelő feszültségek fellángolását élik át Nyugaton, és a keleti lakosságot az ellenfél hatalmak meggyőzik arról, hogy ezek a hatalmak az igazi szövetségeseik, akik megértik és tisztelik őket. Az oktatás sem csodaszer a hivatalos nyelven: Ukrajna (sőt Spanyolország) esetében a helyi nyelvjárások és a hivatalos nyelv közötti nem elhanyagolható különbségek lehetőséget teremtenek az ellenfelek számára a szeparatizmus lángjainak szítására.
A gépi fordítóprogramok használata a NATO és partnerei felhatalmazására az újoncok képzésében vagy a helyszíni fellépésben, a szívükhöz és elméjükhöz legközelebb álló nyelven, azonnali összetartozás-érzést teremthet, és bemutathatja a NATO elfogadott polikulturális vízióját. Mesterséges intelligencia és szabályalapú motorok kerültek összeállításra Lengyelország hivatalos nyelve és az őshonos lemkó kisebbség nyelve közötti fordításhoz, amelyet régóta külföldi hatalmak céloznak. A motorokat lemkó nyelvről lengyelre fordítva értékelték a DARPA támogatásával kifejlesztett metrikák felhasználásával, 31,13-as kétnyelvű értékelési alvizsgálati (BLEU) pontszámot és 54,10-es fordítási szerkesztési arányt (TER) eredményezve. Eközben, a másik irányban a motorok 53,73-as TER és 29,49-es BLEU pontszámot értek el, ami 6,5-szer jobb pontszám, mint a Google Fordító lengyel-ukrán szolgáltatásáé.
Kérem, így hivatkozzon: Orynycz, P., & Dobry, T. (2023). Szívek és nyelvek meghódítása: Egy lengyel-lemkó esettanulmány. A(z) Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC) kiadványában.
[icon name=”badge-check” prefix=”fad”] A hozzájárulás ezen verzióját szakértői értékelés után elfogadták publikálásra, de nem ez a végleges kiadás, és nem tükrözi az elfogadást követő javításokat vagy korrekciókat. A végleges kiadás online elérhető
Bevezetés
A képzési eredmények profitálhatnak a gépi fordítás alkalmazásából az őshonos és kisebbségi nyelvek és dialektusok esetében, amelyek használatát a tudományos irodalom egyre inkább és jelentősen (p ≤ 0.05) élesebb elmével, ellenállóbb pszichével és robusztusabb egészséggel hozza összefüggésbe, nem is beszélve a hatszor alacsonyabb öngyilkossági arányról (Hallett et al., 2007, 398. o.). Az örökölt nyelv használata megerősíthet a külföldi ellenséges befolyással szemben, és az észak-atlanti térségben megakadályozhatja, hogy a célzott népességek orosz vagy más ahistorikus etnolingvisztikai identitásokba essenek a nyelvvesztés pusztító következményeivel való megküzdés során. Míg az anyagok helyi dialektusokra és nyelvekre történő lokalizálása korábban meghaladhatta a háború sújtotta közösségek és kormányok lehetőségeit, a mesterséges intelligencia és a számítógépes nyelvészet legújabb áttöréseinek köszönhetően ma már megfizethető eszközök is elképzelhetők, amelyek olcsóbbak, gyorsabbak és jobbak az embereknél az alacsony erőforrású őshonos és kisebbségi nyelvekre történő fordításban.
A nyelvvesztés problémája nem korlátozódik Európára. Bár a globális nyelvi veszélyeztetettség helyzete talán nem olyan súlyos, mint ahogy az 1990-es évek elején rendelkezésre álló adatok sugallták, a rendelkezésre álló statisztikák mégis borús képet festenek. Egy gyakran idézett, Simmons és Lewis (2013) által „a nagy nyelvi fegyverbe hívásnak” nevezett munkájában Krauss 1992-ben arra figyelmeztetett, hogy a világ nyelveinek felétől 90%-áig terjedő része kihalásra ítéltetett ebben a században. Ezenkívül feltételezte az angolszász világban, ahol az angol dominál, az őshonos nyelvek 90%-ának „dokumentált pusztulási arányát”, és az egész Szovjetunióra, ahol az orosz volt a domináns, becsült 50%-os haldoklási arányt (Krauss, 1992, 5. o.). Húsz évvel később Simmons és Lewis (2013) frissített adatok felhasználásával becsülte, hogy a 7103 élő nyelv közül 1360 (19%) nem öröklődik át a következő generációra (12. o.), ez a szám Kelet-Európában 30%-ra emelkedik (13. o.).
Neurotudomány és tanulási eredmények
A legújabb kutatások azt mutatják, hogy az anyanyelv használata több mentális kapacitást biztosíthat a tanuláshoz, és a teszteredmények jelentősen javulnak. A Massachusetts Institute of Technology (MIT) kutatói által vezetett McGovern Agykutató Intézetben az év elején végzett vizsgálat viszonylag alacsony agyi választ figyelt meg az anyanyelvi ingerekre, amikor funkcionális mágneses rezonancia képalkotó (fMRI) technikával mérték (Malik-Moraleda et al., 2023). Magyarázatként a kutatók azt javasolták, hogy a szakértelem csökkenti a feladathoz szükséges agyi kapacitás mennyiségét (Mesa, 2023). A Világbank számára készült friss tanulmányban Soh, Del Carpio és Wang (2021) megállapította, hogy az anyanyelvtől eltérő oktatási nyelv használata káros lehet, különösen a férfiak számára. A tanulmányban a malajziai diákok matematika és természettudományi teszteredményei jelentősen csökkentek, miután az oktatás nyelvét malájról angolra váltották (Soh et al., 2021, 4., 17., 18–19. o.).
Nemzetbiztonság
A NATO Különleges Műveleti Iskola oktatói, White és Overdeer szerint Oroszország kihasználhatja a célzott társadalmak etnikai megosztottságát a hibrid hadviselés eszközeként, külpolitikai céljainak elérése érdekében (2020, 31–33. o.), mivel az etnolingvisztikai különbségek „könnyen elérhetők és könnyen súlyosbíthatók” (40. o.). Az alábbiakban az etnolingvisztikai viszály szítása és kihasználása Nyugat- és Kelet-Európában egyaránt feltárásra kerül.
Spanyolország: Katalónia
A katalán, egy északkelet-spanyolországi kisebbségi nyelv nyilvános használatát a Franco-kormány 1975-ig betiltotta (Miller & Miller, 1996, 113. o.). Ahelyett, hogy feloldotta volna a viszályt, ez a politika inkább elmélyíthette azt. A The New York Times számára írt cikkben Schwirtz és Bautista (2021) egy 2020. júniusi európai hírszerzési jelentésre hivatkozott, amely szerint az Orosz Föderáció katonai hírszerző rendszerének elit 29155-ös egysége Katalóniában tartózkodott egy 2017-es függetlenségi népszavazás idején, amikor a „titokzatos tüntető csoport”, a Tsunami Democràtic elfoglalta a barcelonai repülőteret és elzárta a Spanyolországot északi szomszédaival összekötő fő autópályát. Három nappal később az orosz Szövetségi Védelmi Szolgálat egyik ezredese és egy magas rangú elnöki tanácsadó közeli rokona, aki mélyen érintett volt Oroszország ukrajnai szeparatistákat támogató erőfeszítéseiben, Moszkvából érkezett egy stratégiai megbeszélésre, hogy megvitassák a katalán függetlenségi mozgalmat (Schwirtz & Bautista, 2021).
Az Orosz Föderáció katalán függetlenségi mozgalom iránti támogatása állítólag még 10 000 katona és $500 milliárd amerikai dollár felajánlását is magában foglalta a függetlenség esetére (Baquero et al., 2022; lásd még Brunet, 2022, 74. o.). Louise I. Shelley, a Virginia állambeli George Mason Egyetem Terrorizmus, Transznacionális Bűnözés és Korrupció Központjának munkatársa szerint Oroszország spanyolországi szeparatista vezetőkkel való kapcsolatfelvétele összhangban van a korábbi viselkedéssel, és kifejtette: „A katalánok és az oroszok közötti kapcsolatok a szovjet korszakra nyúlnak vissza. A Szovjetunió összeomlása előtt magas szintű találkozókat tartottak Barcelonában prominens oroszokkal” (Baquero et al., 2022).
Nyugat-Ukrajna
Ukrajnában a helyi nyelvjárások és az iskolákban tanított irodalmi standard közötti nem elhanyagolható különbségek lehetőséget teremtenek az ellenfelek számára a szeparatizmus lángjainak szítására. A Rating 2012-es jelentése szerint az etnikai ukránoknak mindössze 54%-a használta örökölt nyelvét, 29%-uk oroszt, 17%-uk pedig a kettő keverékét (9. o.). Abban az évben kilenc orosz nyelvű könyv jelent meg minden egyes ukrán nyelvűre, és a nyomtatott média példányainak mindössze 13%-a volt ukrán nyelven írva (Moser, 2016a, 604. o.).
Két évtizeddel ezelőtt az Egyesült Államok Külügyminisztériumának 2002. évi éves emberi jogi jelentése a következőket közölte:
Néhány oroszbarát szervezet az ország keleti részén panaszkodott az ukrán nyelv iskolai és médiabeli fokozott használatára. Azt állították, hogy gyermekeik hátrányos helyzetbe kerültek az egyetemi felvételi vizsgákon, mivel minden jelentkezőnek ukrán nyelvi tesztet kellett tennie.
Külügyminisztérium, 2003, 1758. o.
A ruszinok (rutének) továbbra is hivatalos etnikai csoportként való elismerésüket követelték az országban. A ruszin közösség képviselői ruszin nyelvű iskolákat, ruszin nyelvű tanszéket az Ungvári Egyetemen, valamint azt követelték, hogy a ruszinokat vegyék fel az ország etnikai csoportjai közé a 2001-es népszámlálás során. Ruszin vezetők szerint több mint 700 000 ruszin él az országban.
Külügyminisztérium, 2003, 1759. o.
A Külügyminisztérium által említett szélesebb körű kérdések kiindulópontjaként, amelyek kívül esnek ezen tanulmány hatókörén, Michael Moser, a Harvard Ukrán Kutatóintézet korábbi munkatársa a következőket magyarázta:
A ruszinokat valószínűleg a rutének/ruszinok azon maradványaként lehet a legjobban leírni, akik nem voltak hajlandóak csatlakozni a modern ukrán nemzeti és nyelvi mozgalomhoz… kezdetben ez a vonakodás nem modern értelemben vett ruszin identitáson alapult, hanem oroszbarát nézetekből fakadt, miszerint a rutének/ruszinok/kisoroszok egy oszthatatlan orosz néphez tartoznak, és nincs helye ukrán nemzetnek és ukrán nyelvnek.
Moser, 2016b, 127. o.
2007 júniusában elnöki rendelettel alapították meg Moszkvában az „Orosz Világ Alapítványt”, amely 2011 márciusáig több mint $1 200 000 amerikai dollárral kezdte támogatni az „honfitársakat” Ukrajnában (Moser, 2016a, 607. o.).
Gyűlésre került sor az orosz drámai színházban, Ukrajna legnyugatibb városában, Munkácson, 2008. október 25-én (Wiktorek, 2010, 100. o.). Még arról is érkeztek jelentések, hogy mintegy száz fegyveres, vidéki személy tartózkodott kint (Ukrajinsʹke nacionalʹne objednannja, 2009; lásd még Wiktorek, 2010, 100. o.). Bármi is történt ott, aznap este 20:30-kor megjelent egy „ruszin államiság helyreállításáról” szóló kiáltvány orosz nyelven a rusin.forum24.ru online platformon. Panaszai között szerepel „a ruszin államnyelv felváltása galíciai ukránnal, a lengyel Galícia, a ruszinok északi szomszédjának nyelvével.” (2. Európai [sic] Kárpátaljai [sic] Ruszin Kongresszus, 2008).
Mielőtt elrendelte volna hadseregének nyílt invázióját Ukrajnába egy nagyszabású „különleges katonai művelet” végrehajtására, az Orosz Föderáció elnöke egy teljes bekezdést szentelt Kárpátalja sorsának Az oroszok és ukránok történelmi egységéről című esszéjében:
Külön tárgyalom Kárpátalja sorsát, amely Ausztria-Magyarország összeomlása után Csehszlovákiához került. A helyi lakosság jelentős részét ruszinok alkották. Bár ma már ritkán emlékeznek rá, Kárpátalja szovjet csapatok általi felszabadítása után a terület ortodox lakosságának kongresszusa támogatta Kárpátalja beolvasztását az Orosz Szovjet Szövetségi Szocialista Köztársaságba, vagy közvetlenül a Szovjetunióba, mint különálló, kárpát-orosz köztársaságot.
Putyin, 2021
A régióban egy másik incidens során a lengyel szélsőjobboldali Falanga szervezet két tagja, akik orosz szeparatisták között tartózkodtak Kelet-Ukrajnában, 2018-ban felgyújtották az őshonos magyar etnolingvisztikai kisebbség kulturális központját Ungvár regionális fővárosában, benzinnel leöntve és Molotov-koktélt dobva rá (Górzyński, 2018).
Egészség és biztonság
Öngyilkossági hajlam
Hatszor magasabb öngyilkossági arányt figyeltek meg azokban a közösségekben, ahol kevesebb mint a fele számolt be örökölt nyelvének társalgási szintű ismeretéről (Hallett et al., 2007, 398. o.). Pozitívumként megemlítendő, hogy a fiatalok öngyilkossági aránya nullára csökkent minden esetben, kivéve egyet, ahol a többség arról számolt be, hogy képes társalogni örökölt nyelvén (397. o.). Pezzia és Hernandez 2022-es tanulmányában azok, akik nem beszéltek folyékonyan örökölt nyelvet, de szüleik igen (95. o.), a legnagyobb valószínűséggel öngyilkossági gondolatokkal küzdöttek (98. o.). A nyelvvesztés és az öngyilkossági gondolatok közötti összefüggés magyarázataként Pezzia és Hernandez az „akkulturációs stresszt vagy társadalmi kirekesztést” javasolja, amely abból ered, hogy az etnikai csoport teljes jogú tagjaként való elfogadást megakadályozza a nyelv folyékony ismeretének hiánya (100. o.).
Depresszió
Az életkor, nem, iskolai végzettség, anyagi helyzet és etnikai csoporttagság kontrollálása után a kutatók megállapították, hogy az identitás elrejtése az örökölt nyelv nyilvános használatának elkerülésével (ezt nyelvi elkerülésnek nevezik) statisztikailag szignifikáns (p = 0.006) előrejelzője annak, hogy valaki „depressziósnak” minősíthető, ha Kroenke és Spitzer 9-es számú beteg-egészségügyi kérdőívén 5 vagy annál magasabb pontszámot ér el (Olko et al., 2023, 5–6. o.). Elméleti mechanizmusként a kutatók az etnikai diszkrimináció által kiváltott krónikus stresszt említették, amely a hipotalamusz-hipofízis-mellékvese tengely tartós hiperaktivitásához, és ebből eredő megnövekedett kortikotropin-felszabadító faktor és kortizol szinthez vezet, utalva Willner (2017), valamint Slavich és Irwin (2014) munkájára.
Cukorbetegség
A szocioökonómiai tényezők korrigálása után a diabetes mellitus szignifikánsan (p = 0.005) kevésbé volt elterjedt az őshonos nyelvtudással rendelkező közösségekben (Oster et al., 2014, 9. o.).
Dohányfogyasztás
Az angol nyelvhez jobban akkulturálódott állapot szignifikánsan összefüggésbe hozható a dohányzással az idősebb ázsiai-amerikai serdülők körében New York Cityben (Rosario-Sim & O’Connell, 2009). Egy másik tanulmányban az angol nyelv otthoni használata magasabb dohányzási prevalencia rátával járt együtt az ázsiai-amerikai fiatalok körében (p = 0.021), akárcsak a magas angol nyelvtudás (p = 0.040) (Chen et al., 1999, 325. o.). A spanyolajkú lányok körében azok, akik angolul beszéltek szüleikkel, többet dohányoztak, mint azok, akik angolul és spanyolul is beszéltek szüleikkel (p < 0.0001), valamint azok a lányok, akik spanyolul beszéltek szüleikkel (p < 0.01) (Epstein et al., 1998, 586. o.).
Szerhasználat és támadás
Az Ausztrál Statisztikai Hivatal (2011/2012) szerint a tizenöt és huszonnégy év közötti őslakos fiatalok, akik őshonos nyelvet beszéltek, kisebb valószínűséggel használtak illegális szereket (16% vs. 26%), kisebb valószínűséggel számoltak be mértéktelen alkoholfogyasztásról az előző két hétben (18% vs. 34%), és kisebb valószínűséggel váltak fizikai vagy fenyegető erőszak áldozatává az előző évben (25% vs. 37%).
Eddigi megoldások
Neurális mesterséges intelligencia
A neurális gépi fordítás áttörése, amelyet egy nemzetközi csapat a Defense Advanced Research Projects Agency (DARPA) finanszírozásával a Broad Operational Language Translation (BOLT) projekt keretében (Cho et al., 2014), valamint a Google (Sutskever et al., 2014) ért el, olyan motorokat hozott létre, amelyek képesek az emberi teljesítménnyel egyenértékű minőségi pontszámokat elérni. A neurális motorok képzéséhez azonban több adatra van szükség, mint amennyi általában rendelkezésre áll az alacsony erőforrású nyelvek esetében.
Szabályalapú gépi fordítás
A múlt szabályalapú fordítómotorjait általában pénzpazarlásnak tekintették (Hajič et al., 2000, 7. o.), kivéve a prágai RUSLAN rendszert, amelyet a szovjet alapítású Kölcsönös Gazdasági Segítség Tanácsa (KGST) finanszírozott, és amely cseh-orosz fordításokat készített nagyszámítógépes operációs rendszerek dokumentációjához (7. o.), ahol öt mondatból kettő helyes volt, további kettő csak kisebb hibákat tartalmazott, és mindössze egy igényelt jelentős szerkesztést vagy újrafordítást (8. o.).
A prágai, cseh-orosz szabályalapú rendszerek eredményeivel kapcsolatos nyilvánvaló csalódás fő okai az voltak, hogy maga a feladat túl bonyolult volt, és hogy a cseh és az orosz nyelv nem áll eléggé közel egymáshoz ahhoz, hogy egy ilyen megközelítés életképes legyen. A listához hozzáadhatók a valótlan elvárások és az objektív értékelési metrikák hiánya. Eközben a cseh nyelvről szlovákra és lengyelre történő fordítások eredményei, amelyek mind közelebbi nyugati szláv nyelvek, meglehetősen biztatóak voltak (Hajič et al., 2000, 12. o.).
Hibrid neurális/szabályalapú gépi fordítás
Az Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC) konferencián bemutatott eredmények szerint egy szabályalapú lemkó-lengyel motor és egy szabályalapú lengyel-angol motor kombinálásával készültek el a világ első publikált gépi fordítási eredményei lemkóról angolra (Orynycz et al., 2021). A következő évben a fordított irányú fordításokat a rendszer módosításával és fordított működtetésével állították elő (Orynycz, 2022). Az ezen a motoron végrehajtott fejlesztések, annak felülvizsgálata és szókincsének bővítése később 35%-os fordítási minőségjavuláshoz vezettek (Orynycz, 2023).
Új megoldások
Szabályalapú gépi fordítási szakértői rendszer
Egy következtető motort kézzel kódoltak tesztvezérelt fejlesztés (TDD) segítségével, hogy tükrözze a szakterületi szakértők munkájával összeállított tudásbázisban található igazságokat. Ez a megközelítés lehetővé teszi a külföldi beavatkozások manuális kiküszöbölését és az orosz, valamint más jövevényszavak tisztítását is. A felhasznált szótárak között szerepelt Horoszczak kétirányú lengyel-lemkó szótára (2004), Pyrtej lemkó-ukrán szótára (2004), Duda ukrán-lemkó szótára (2011), és Rieger lemkó-lengyel szójegyzéke (1995), valamint a Bartne faluból származó felvételeken alapuló lemkó-lengyel szójegyzéke (2016). Fontański és Chomiak (2000), valamint Pyrtej (2013) nyelvtanait vették figyelembe a szavak nyelvtani kategóriák, például szám, eset és nem szerinti ragozására vonatkozó szabályok kódolásakor.
Transzformer mesterséges intelligencia
A neurális gépi fordítás áttörését szorosan követte a Google Brain és a Google Research tudósai által bevezetett Transformer architektúra, amely kizárólag figyelmi mechanizmusokon alapul, és teljesen elhagyja a rekurrenciát és a konvolúciókat (Vaswani et al., 2017). Ehhez a kísérlethez transzformer alapú mesterséges intelligencia modelleket képeztünk ki a lengyelről lemkó nyelvre történő fordításhoz, és tudomásunk szerint mi vagyunk az elsők, akik eredményeket publikálnak.
Anyagok és módszerek
Anyag
Adatok
Mesterséges intelligencia modelleket hoztunk létre egy korpusz felhasználásával, amely 1 611 352 forrásszót (a Microsoft Word 365 szerint) tartalmazott, 112 507 sorban, amelyeket lengyel születésű, anyanyelvi lemkó beszélők írtak, valamint azok lengyel fordításait a Google Cloud Platform Translation alkalmazásprogramozási felület (API) segítségével, amelyet úgy konfiguráltak, hogy standard ukrán nyelvről fordítson neurális gépi fordítás használatával.
A lemkó (más néven lemkó ruszin) genetikailag a délnyugati ukrán dialektusrendszerhez tartozik, amelyen belül a hangsúly rögzített a feltételezett (utolsó előtti) szótagra (Danylenko, 2020). Az ilyen dialektusok őshonosak a jelenleg Lengyelország, és 1993 óta a Szlovák Köztársaság fennhatósága alá tartozó területeken.
A két világháború közötti Lengyelországban a kormány különálló lemkó, hucul és bojkó identitásokat támogatott, hogy ellensúlyozza az ukrán mozgalmat, amelynek tanárait elbocsátották (Moser, 2016b, 128. o.). 1935-ben az oroszbarát tanárokat lengyelek váltották fel, és a lemkó nyelvet végül 1937-ben eltávolították az iskolákból (128. o.). A lengyelországi lemkó beszélők mintegy kétharmadát 1945 és 1947 között Ukrajnába deportálták, a fennmaradó 40 000–50 000 főt pedig elsősorban a kommunista Lengyelország újonnan annektált, korábban német területeire telepítették át (131. o.). Lengyelország 2021-es népszámlálásának előzetes eredményei szerint 12 700-an jelölték meg a „lemkó” etnikumot (Główny Urząd Statystyczny, 2023, 3. o.).
Módszerek
Előfeldolgozás
Először minden szöveget kisbetűssé alakítottunk. Ezután szóközt illesztettünk minden nem alfanumerikus karakter elé és mögé. Minden sor elejéről és végéről eltávolítottuk a felesleges szóközöket. Ezt követően a fenti korpuszt Moslem (2023a) szkriptjével dolgoztuk fel a párhuzamos adatkészletek tisztítására és szűrésére (commit db6f441), így 33 612 sor maradt, amely 610 990 forrásszót tartalmazott a Microsoft Word 365 számlálása szerint.
Alszó-tokenizálás
Unigram alszó-modelleket képeztünk ki Moslem (2021a) szkriptjével (commit fbf2488). Ezután ezeket a modelleket használtuk a forrás- és célnyelvi szöveg tokenizálására ugyanazon commit második alszó-szkriptjével (Moslem, 2021b).
Adatfelosztás
A fenti korpuszból 2 000 sort különítettünk el értékelésre Moslem (2023b) erre a célra készült szkriptjével (commit e6decb7).
Mesterséges intelligencia modellek képzése
Mesterséges intelligencia modelleket képeztünk ki az OpenNMT neurális gépi fordítási eszköztár TensorFlow verziójával, amely a Harvard seq2seq-attn szekvencia-szekvencia modelljének utódja figyelmi mechanizmussal (Klein et al., 2017, 68. o.). A képzési és értékelési ciklus indítására szolgáló parancsot a Transformer modell automatikus konfigurációjával indítottuk el. Az automatikus értékelést is engedélyeztük, és úgy állítottuk be, hogy 5 000 lépésenként fusson a kétnyelvű értékelési alvizsgálat (BLEU) metrika használatával, és exportáljon egy modellt, amikor új csúcspontot ért el. A képzést a
Következtető motor
Egy fordítási következtető motort készítettünk Klein Python kiszolgáló kliens szkriptje (commit 2b196ff) (2021) alapján, amelyet módosítottunk, hogy befogadja a forrás- és célnyelvi alszó-tokenizálási modelleket, valamint optimalizálja a szóközöket és a nagybetűs írást, hogy jobban megfeleljen a mesterséges intelligencia modellek és a végfelhasználók elvárásainak. A fordítási előrejelzéseket fájlba mentettük a későbbi minőségértékelés céljából.
Minőségértékelés
A fordítások minőségét olyan metrikák felhasználásával értékeltük, amelyek fejlesztését a DARPA finanszírozta: mind a BLEU (Papineni et al., 2002), mind a Translation Edit Rate (TER) (Snover et al., 2006). Magukat a pontszámokat az Amazon Research által Post (2018) által kifejlesztett iparági szabványos módszerekkel számítottuk ki.
Eredmények
Fordítási minőségi pontszámok
A kísérleti szabályalapú szakértői rendszer minden más rendszert felülmúlt minden metrika szerint, amikor lengyelről lemkóra és fordítva fordított.
Lengyel–lemkó fordítás minősége
Lengyelről lemkóra történő fordításkor a kísérleti szakértői szabályalapú rendszer 29,49 BLEU kétnyelvű értékelési alvizsgálati minőségi pontszámot ért el, ami 6,50-szer jobb, mint a Google Fordító ukrán szolgáltatása. Eközben a kísérleti mesterséges intelligencia Transformer neurális gépi fordítási rendszer 15,90 BLEU pontszámot ért el 30 000 képzési lépés után, ami 3,50-szer jobb volt, mint a Google Fordító ukrán szolgáltatása. Az alternatív TER metrika használatával mérve a kísérleti szakértői, szabályalapú rendszer 53,73 TER pontszámot ért el, ami 61%-kal jobb, mint a Google Fordító ukrán szolgáltatása.

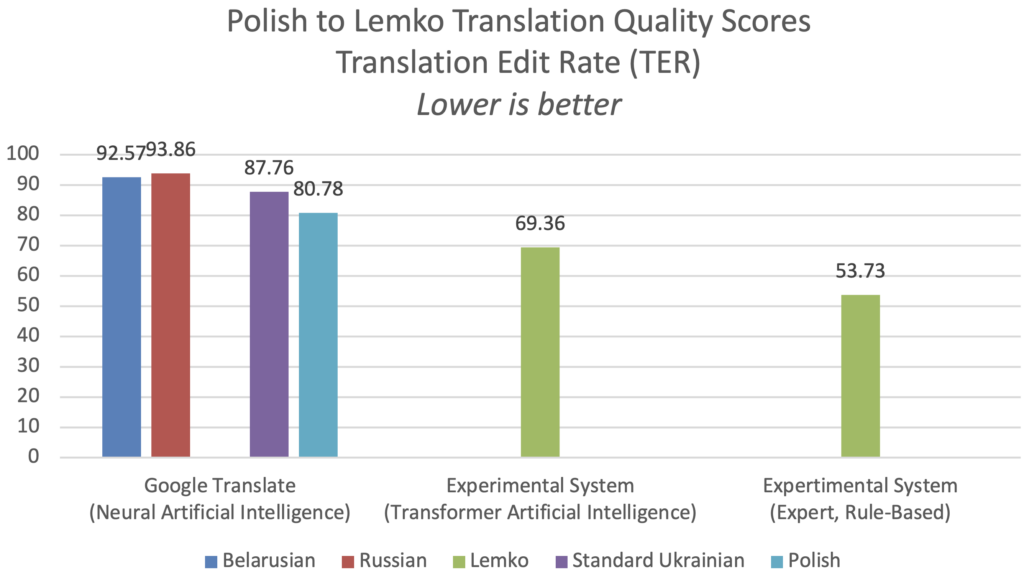
Lemkó–lengyel fordítás minősége
A kísérleti, szabályalapú szakértői rendszer minden más rendszert felülmúlt minden metrika szerint, amikor lemkóról lengyelre fordított, 31,13 BLEU kétnyelvű értékelési alvizsgálati minőségi pontszámot ért el, ami 1,4-szer jobb volt, mint a Google Fordító ukrán szolgáltatásának 22,16 BLEU pontszáma.
Példák
| Angol jelentés (emberi fordító) | Például a szövegekben, és én főleg szövegeket tanulmányozok, van egy forrásom, azt írták: az osztrákok gyilkoltak minket, akkor mit fognak tenni velünk azok a szörnyű moszkvaiak, akikkel megpróbálnak minket megijeszteni? | |||||
| Lengyel (emberi fordító) | Na przykład oni w tekstach, a ja głównie badam teksty, mam takie źródło, pisali: Austriacy nas mordowali, to co zrobią ci straszni Moskale, którymi nas straszą? | |||||
| Igazság: Lemkó referencia (anyanyelvi beszélő) | І они наприклад в текстах, а я головні досліджам тексты, то значыт мам такє джерело, писали: но Австриякы нас мордували, то што зроблят тоты страшны Москалі, котрыма нас страшат? | I ony napryklad v tekstach, a ja holovni dosljidžam tekstŷ, to značŷt mam takie džerelo, pysaly: no Avstryjakŷ nas morduvaly, to što zrobljat totŷ strašnŷ Moskalji, kotrŷma nas strašat? | ||||
| Rendszer | Fordítási hipotézisek | Minőségi pontszámok | ||||
| Cirill | Átírás | BLEU | TER | |||
| Kísérleti | Szakértői rendszer (szabályalapú) | Наприклад они в текстах, а я головні бадам текстий, мам такы джерело, писали: Австриякы нас мордували, то што зроблят тоты страшны москале, котрыма нас страшом? | Napryklad ony v tekstach, a ja holovni badam tekstyj, mam takŷ džerelo, pysaly: Avstryjakŷ nas morduvaly, to што zrobljat totŷ strašnŷ moskale, kotrŷma nas strašom? | 46.32 | 34.48 | |
| Mesterséges intelligencia (Transformer) | Примірово, в текстах, а я головні в заміріню тексту, маме джерело, писали: австриякы австриякы мордували, же то што зроблят стабілизацию тому, котрыма нас престрашыли? | Prymirovo, v tekstax, a ja holovni v zamirinju tekstu, mame džerelo, pysaly: avstryjakŷ avstryjakŷ morduvaly, že to što zrobljat stabilyzacyju tomu, kotrŷma nas prestrašŷly? | 27.65 | 55.17 | ||
| Google Fordító | Lengyel | На прзиклад оні в текстах, а я ґлувнє бадам тексти, мам такє зьрудло, пісалі: Аустряци нас мордовалі, то цо зробьон ці страшні Москалє, ктуримі нас страшон? | Na przyklad oni v tekstach, a ja gluvnje badam teksty, mam takje źrudlo, pisalji: Austriacy nas mordovalji, to co zrobjon ci strašni Moskalje, kturymi nas strašon? | 14.21 | 68.97 | |
| Ukrán | Наприклад, у своїх текстах, а я в основному досліджую тексти, у мене є таке джерело, вони писали: Австрійці нас повбивали, що будуть робити ті страшні москалі, якими вони нам погрожують? | Napryklad, u svojix tekstax, a ja v osnovnomu doslidžuju teksty, u mene je take džerelo, vony pysaly: Avstrijci nas povbyvaly, ščo budutʹ robyty ti strašni moskali, jakymy vony nam pohrožujutʹ? | 9.43 | 82.76 | ||
| Orosz | Например, в их текстах, а я в основном исследую тексты, у меня есть такой источник, они писали: Нас убили австрийцы, что будут делать те страшные москвичи, которыми они нам угрожают? | Naprimer, v ix tekstax, a ja v osnovnom issleduju teksty, u menja estʹ takoj istočnik, oni pisali: Nas ubili avstrijcy, čto budut delatʹ te strašnye moskviči, kotorymi oni nam ugrožajut? | 9.43 | 86.21 | ||
| Belarusz | Напрыклад, у сваіх тэкстах, а я ў асноўным тэксты дасьледую, у мяне ёсьць такая крыніца, яны пісалі: Аўстрыйцы нас забілі, што будуць рабіць тыя страшныя маскалі, якімі яны нам пагражаюць? | Napryklad, u svaix tèkstax, a ja ŭ asnoŭnym tèksty das′leduju, u mjane ës′c′ takaja krynica, jany pisali: Aŭstryjcy nas zabili, što buduc′ rabic′ tyja strašnyja maskali, jakimi jany nam pahražajuc′? | 4.99 | 96.55 | ||
Megbeszélés
Politikai vonatkozások
A tanulási, közegészségügyi és biztonsági eredmények javulhatnak, ha az oktatási, képzési, közösségi tájékoztató és egyéb anyagokat a nemzeti szabványos nyelvek mellett regionális dialektusokra és nyelvekre is lokalizálják. Az emberi erőforrás-kapacitások túlterhelésének elkerülése érdekében a nyelvészek feladata lehetne a szakértői és mesterséges intelligencia gépi fordítási rendszerek kimenetének utószerkesztése, szemben a kézi fordítással. A fordított anyagokhoz való megfizethetőbb hozzáférés javulást hozhat a szociális szolgáltatásokban az alulfejlett területeken. Stonewall et al. a többnyelvűséget, és ezáltal az inkluzivitást, előkelő helyen említik az alulfejlett népességek bevonására vonatkozó legjobb gyakorlatok listáján (2017). Az Európai Unió olyan kutatásokat finanszíroz, amelyek szerint a gépi fordítás felhasználható a polgári részvétel elősegítésére, valamint az alulfejlett közösségek közegészségügyének és biztonságának erősítésére (Nurminen & Koponen, 2020).
Technológiai vonatkozások
A dolgok jó úton haladnak afelé, hogy a lemkó nyelvre történő kereskedelmileg életképes gépi fordítás egy gombnyomásra valósággá váljon. A szakértői, szabályalapú rendszerek folyamatos, tesztvezérelt fejlesztése úgy tűnik, a leggyorsabb utat kínálja a szuperhumán fordítási minőségi pontszámok eléréséhez. A transzformer alapú mesterséges intelligencia rendszerek hosszú távon győzhetnek.
A mesterséges intelligencia képzési eljárásának néhány finomhangolása kísérletezést érdemel. A korpuszszűrő szkript túlzottan buzgó lehetett ehhez a feladathoz, és túlságosan lecsökkentette a korpusz méretét, akadályozva a teljesítményt. A szkript kihagyható egy jövőbeli kísérletben. A túltanulás akadályozhatja a pontszámokat, és talán az 5 000 lépéses értékelési intervallumot rövidíteni kellene. A szakértői szabályalapú rendszer használata a korpuszok lemkóról lengyelre történő fordítására a Google Cloud Platform szolgáltatással szemben jobb eredményeket hozhat. Az automatikus helyesírás-ellenőrző modulok beépítése globálisan is javíthatja a pontszámokat.
Az orosz és más idegen nyelvi interferencia programozottan ellensúlyozható lenne a jövevényszavak keresés-csere algoritmusokkal történő tisztításával. A nemzeti nyelvi akadémiák és más hatóságok hasznosnak találhatják az ilyen képességeket. Lehetséges, hogy a fordítási minőség már elérte a szuperhumán szintet, ami egy olyan hipotézis, amelyet jövőbeli kísérletekben tesztelni lehetne.
Érdekellentétek nyilatkozata
A fő szerző minőségellenőrzési specialistaként dolgozik a Google Fordító San Franciscó-i projektjében.
Hivatkozások
2. Európai [sic] Kárpátaljai [sic] Ruszin Kongresszus [rusin]. (2008. október 25.).MEMORANDUM 2-go Evropejskogo Kongressa Podkarpatskix Rusinov o prinjatii AKTA PROVOZGLAŠENIJA vosstanovlenija rusinskoj gosudarstvennosti [A Kárpátaljai Ruszinok Második Európai Kongresszusának memorandumja a Ruszin Államiság Helyreállításáról szóló Kiáltvány elfogadásáról] [Online fórumbejegyzés]. Kárpátaljai Ruszinok Információs Ügynöksége. IAPR. Kárpátaljai Ruszinok Fóruma.
http://rusin.forum24.ru/?1-9-0-00000005-000-0-0-1224955832
Ausztrál Statisztikai Hivatal, (2012). Kultúra, örökség és szabadidő: Aborigin és Torres-szigeteki nyelvek beszélése. Aborigin és Torres-szigeteki jólét: Fókuszban a gyermekek és fiatalok. (Eredeti mű megjelent: 2011) Letöltve: 2023. május 1., innen: https://www.abs.gov.au/ausstats/abs@.nsf/Latestproducts/1E6BE19175C1F8C3CA257A0600229ADC
Baquero, A., Hall, K.G., Tsogoeva, A., Albalat, J.G., Grozev, C., Bagnoli, L., IStories, & Vergine, S. (2022. május 8.). Szeparatizmus szítása, Bitcoin ígéretek: Hogyan sürgetett egy orosz ügynök katalán vezetőket, hogy szakítsanak Madriddal. Szervezett Bűnözés és Korrupció Jelentési Projekt (OCCRP). https://www.occrp.org/en/investigations/fueling-secession-promising-bitcoins-how-a-russian-operator-urged-catalonian-leaders-to-break-with-madrid
Brunet, F. (2022). A katalán szeparatizmus gazdaságtana. Cham: Springer Nature Switzerland AG. https://doi.org/10.1007/978-3-031-14451-6
Chen, X., Unger, J.B., Cruz, T.B., & Johnson, C.A. (1999). Ázsiai-amerikai fiatalok dohányzási szokásai Kaliforniában és kapcsolatuk az akkulturációval. Journal of Adolescent Health, 24(5), 321-328. https://doi.org/10.1016/S1054-139X(98)00118-9
Cho, K., van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Kifejezésreprezentációk tanulása RNN kódoló-dekódolóval statisztikai gépi fordításhoz. A 2014-es Természetes Nyelvfeldolgozás Empirikus Módszereinek Konferenciájának (EMNLP) Előadásai, 1724–1734 http://dx.doi.org/10.3115/v1/D14-1179
Danylenko, A. (2020). „Kárpát-ruszin”, ben: A szláv nyelvek és nyelvészet online enciklopédiája, főszerkesztő: Marc L. Greenberg. Online megtekintve: 2023. június 13.
http://dx.doi.org/10.1163/2589-6229_ESLO_COM_031960
Külügyminisztérium (2003). S.Prt. 108-30, I. kötet – ORSZÁGOS JELENTÉSEK AZ EMBERI JOGI GYAKORLATOKRÓL 2002-RE, I. KÖTET. Washington, D.C.: U.S. Government Publishing Office. https://www.govinfo.gov/app/details/CPRT-108JPRT86917/CPRT-108JPRT86917
Duda, I. (2011). Lemkivsʹkyj slovnyk [Lemkó szótár]. Ternopil: Aston.
Epstein, J. A., Botvin, G.J., & Diaz, T. (1998). Nyelvi akkulturáció és nemi hatások a dohányzásra a spanyolajkú fiatalok körében. Preventive medicine, 27(4), 583–589. https://doi.org/10.1006/pmed.1998.0329
Fontański, H., & Chomiak, M. (2000). Gramatyka języka łemkowskiego [A lemkó nyelv nyelvtana]. Katowice: „Śląsk” Sp. z o.o. Wydawnictwo Naukowe.
Główny Urząd Statystyczny (2023). Wstępne wyniki NSP 2021 w zakresie struktury narodowo-etnicznej oraz języka kontaktów domowych [A 2021-es népszámlálás előzetes eredményei a nemzeti és etnikai szerkezet, valamint az otthon használt nyelv tekintetében]. Letöltve: 2023. június 11., innen: https://stat.gov.pl/spisy-powszechne/nsp-2021/nsp-2021-wyniki-wstepne/wstepne-wyniki-narodowego-spisu-powszechnego-ludnosci-i-mieszkan-2021-w-zakresie-struktury-narodowo-etnicznej-oraz-jezyka-kontaktow-domowych,10,1.html
Górzyński, O. (2018. március 3.). Oroszország titkos kampánya Kelet-Európa felgyújtására. The Daily Beast. https://www.thedailybeast.com/russias-covert-campaign-inflaming-east-europe
Hajič, J., Hric, J., & Kuboň, V. (2000. április). Nagyon közeli nyelvek gépi fordítása. In Hatodik Alkalmazott Természetes Nyelvfeldolgozási Konferencia (7–12. o.). http://dx.doi.org/10.3115/974147.974149
Hallett, D., Chandler, M.J., & Lalonde C.E. (2007): Aborigin nyelvtudás és ifjúsági öngyilkosság. Kognitív Fejlődés. 22(3), 392–399. https://doi.org/10.1016/j.cogdev.2007.02.001
Horoszczak, J. (2004). Słownik łemkowsko-polski, polsko-łemkowski [Lemkó-lengyel és lengyel-lemkó szótár], Warszawa: Rutenika.
Klein, G. (2021). Következtetés TensorFlow Servinggel. Letöltve: 2023. június 5., innen: https://github.com/OpenNMT/OpenNMT-tf/blob/master/examples/serving/tensorflow_serving/ende_client.py
Klein, G., Kim, Y., Deng, Y., Senellart, J., & Rush, A.M. (2017). OpenNMT: Nyílt forráskódú eszköztár neurális gépi fordításhoz. In A Számítógépes Nyelvészet Szövetségének 55. Éves Találkozójának Előadásai – Rendszerbemutatók, 67–72. o. https://doi.org/10.18653/v1/P17-4012
Krauss, M. (1992). A világ nyelvei válságban. Language, 68(1), 4–11. https://doi.org/10.1353/lan.1992.0075
Malik-Moraleda, S., Jouravlev, O., Mineroff, Z., Cucu, T., Taliaferro, M., Mahowald, K., Blank, I., & Fedorenko, E. Poligloták és hiperpoligloták nyelvi hálózatának funkcionális jellemzése precíziós fMRI-vel. Cold Spring Harbor Laboratory. Előzetes online publikáció. https://doi.org/10.1101/2023.01.19.524657
Mesa, N. (2023. február 3.). Anyanyelved különleges helyet foglal el az agyadban, még akkor is, ha 10 nyelven beszélsz. Science, https://doi.org/10.1126/science.adh0055
Miller, H., & Miller, K. (1996). Nyelvpolitika és identitás: a katalán eset. International Studies in Sociology of Education, 6(1). https://doi.org/10.1080/0962021960060106
Moser, M. (2016a). Nyelvpolitika a kortárs Ukrajnában (2010. február 25. – 2011. február 25.). In Új hozzájárulások az ukrán nyelv történetéhez (601–619. o.). Canadian Institute of Ukrainian Studies Press. https://www.ciuspress.com/product/new-contributions-to-the-history-of-the-ukrainian-language/
Moser, M. (2016b). Ruszin: Egy új-régi nyelv nemzetek és államok között. In: Tomasz Kamusella, Motoki Nomachi, Catherine Gibson (szerk.), The Palgrave Handbook of Slavic Languages, Identities and Borders, 124–139. o. https://doi.org/10.1007/978-1-137-34839-5_7
Moslem, Y. (2021a). SentencePiece modellek képzése a forrás- és célszöveghez. Letöltve: 2023. június 4., innen: https://github.com/ymoslem/MT-Preparation/blob/main/subwording/1-train_unigram.py
Moslem, Y. (2021b). A forrás- és célszöveg fájlok szubszavazása. Letöltve: 2023. június 4., innen: https://github.com/ymoslem/MT-Preparation/blob/main/subwording/2-subword.py
Moslem, Y. (2023a). Párhuzamos adathalmazok szűrése/tisztítása gépi fordításhoz. Letöltve: 2023. június 4., innen: https://github.com/ymoslem/MT-Preparation/blob/main/filtering/filter.py
Moslem, Y. (2023b). A párhuzamos adathalmaz felosztása képzési, fejlesztési és tesztelési adathalmazokra gépi fordításhoz. Letöltve: 2023. június 4., innen:
https://github.com/ymoslem/MT-Preparation/blob/main/train_dev_split/train_dev_test_split.py
Nurminen, M., & Koponen, M. (2020). Gépi fordítás és méltányos hozzáférés az információhoz. Translation Spaces, 9(1), 150–169. https://doi.org/10.1075/ts.00025.nur
Olko, J., Galbarczyk, A., Maryniak, J., Krzych-Miłkowska, K., Iglesias Tepec, H, de la Cruz, E., Dexter-Sobkowiak, E., & Jasienska, G. (2023): A hátrányos helyzet spirálja: Etnolingvisztikai diszkrimináció, akkulturációs stressz és egészség a mexikói Nahua őslakos közösségekben. American Journal of Biological Anthropology, 1–15. https://doi.org/10.1002/ajpa.24745
Orynycz, P. (2022, május). Mondd jól: Az AI neurális gépi fordítás képessé teszi az új beszélőket a lemkó nyelv újjáélesztésére. In Mesterséges intelligencia az HCI-ben: 3. Nemzetközi Konferencia, AI-HCI 2022, a 24. HCI Nemzetközi Konferencia, HCII 2022 részeként, virtuális esemény, 2022. június 26. – július 1., Előadások (pp. 567–580). Cham: Springer International Publishing. https://doi.org/10.1007/978-3-031-05643-7_37
Orynycz, P. (2023, július). BLEU kilátások a veszélyeztetett nyelvek revitalizációjához: a lemkó-ruszin nyelv neurális mesterséges intelligencia fordítási pontossága szárnyal. In Ember-számítógép interakció nemzetközi konferencia (pp. 135–149). Cham: Springer Nature Switzerland. https://doi.org/10.1007/978-3-031-35894-4_10
Orynycz, P., Dobry, T., Jackson, A., & Litzenberg, K. (2021). Igen, beszélek… AI neurális gépi fordítás többnyelvű képzésben. In Proceedings of the Interservice/Industry Training, Simulation, and Education Conference (I/ITSEC). https://www.xcdsystem.com/iitsec/proceedings/index.cfm?Year=2021&AbID=96953&CID=862
Oster, R.T., Grier, A., Lightning, R., Mayan, M.J., & Toth, E.L. (2014). Kulturális folytonosság, hagyományos őslakos nyelv és cukorbetegség az Albertai Első Nemzetek körében: vegyes módszertanú tanulmány. International Journal for Equity in Health, 13(92), 1–11. https://doi.org/10.1186/s12939-014-0092-4
Papineni, K., Roukos, S., Ward, T., & Zhu, W.J. (2002, július). BLEU: módszer a gépi fordítás automatikus értékelésére. In Proceedings of the 40th annual meeting of the Association for Computational Linguistics (pp. 311–318). https://doi.org/10.3115/1073083.1073135
Pezzia, C., & Hernandez, L.M. (2022). Öngyilkossági gondolatok egy etnikailag vegyes, guatemalai hegyvidéki közösségben. Transcultural Psychiatry. 59(1), 93–105. https://doi.org/10.1177/1363461520976930
Post, M. (2018). Felszólítás a BLEU pontszámok jelentésének egyértelműsítésére. In Proceedings of the Third Conference on Machine Translation: Research Papers, pp. 186–191. Brussels: Association for Computational Linguistics http://dx.doi.org/10.18653/v1/W18-6319
Putin, V. Ob istoričeskom edinstve russkix i ukraincev [Az oroszok és ukránok történelmi egységéről]. Letöltve: 2023. május 15., innen: http://kremlin.ru/events/president/news/66181
Pyrtej, P. (2004). Korotkyj slovnyk lemkivsʹkyx hovirok [A lemkó dialektusok rövid szótára]. Ivano-Frankivsʹk: Siversija MB.
Pyrtej, P. (2013). Lemkivsʹki hovirky. Fonetyka i morfolohija [A lemkó dialektusok. Fonetika és morfológia]. Gorlice: Zjednoczenie Łemków.
Rating, (2012). Pytannja movy: rezulʹtaty ostannix doslidženʹ 2012 roku [A nyelvi kérdés: A legújabb kutatások eredményei 2012-ben]. Letöltve: 2023. augusztus 26., innen: https://ratinggroup.ua/files/ratinggroup/reg_files/rg_mova_dynamika_052012.pdf
Rieger, J. (1995). Słownictwo i nazewnictwo łemkowskie [Lemkó szókincs és nómenklatúra]. Warszawa: Wydawnictwo Naukowe Semper.
Rieger, J. (2016). Mały słownik łemkowkiej wsi Bartne [Bartne lemkó falu kis szótára]. Warszawa: Wydawnictwo Uniwersytetu Warszawskiego.
Rosario-Sim, M.G., & O’Connell K.A. (2009). A depresszió és a nyelvi akkulturáció összefüggése a dohányzással az idősebb ázsiai-amerikai serdülők körében New York Cityben. Public Health Nursing 26(6), 532–542. https://doi.org/10.1111/j.1525-1446.2009.00811.x
Schwirtz, M., & Bautista, J. (2023, szeptember 23) Házas Kreml-kémek, egy árnyékos moszkvai küldetés és zavargások Katalóniában. The New York Times. Letöltve: 2023. május 16., innen: https://www.nytimes.com/2021/09/03/world/europe/spain-catalonia-russia.html
Simmons, G.F., & Lewis, M.P. (2013). A világ nyelvei válságban: 20 éves frissítés. In E. Mihas, B. Perley, G. Rei-Doval & K. Wheatley (Eds.), Válaszok a nyelvi veszélyeztetettségre: Mickey Noonan tiszteletére. Új irányok a nyelvi dokumentációban és nyelvi revitalizációban (pp. 3–20). John Benjamins Publishing Company. https://doi.org/10.1075/slcs.142.01sim
Slavich, G.M., & Irwin, M.R. (2014). A stressztől a gyulladásig és a súlyos depressziós rendellenességig: a depresszió szociális jelátviteli elmélete. Psychological Bulletin, 140(3), 774–815. https://doi.org/10.1037/a0035302
Snover, M., Dorr, B., Schwartz, R., Micciulla, L., & Makhoul, J. (2006). Fordítási szerkesztési arány vizsgálata célzott emberi annotációval. In Proceedings of the 7th Conference of the Association for Machine Translation in the Americas: Technical Papers, (pp. 223–231). https://aclanthology.org/2006.amta-papers.25
Soh, Y.C., Del Carpio, X.V., & Wang, L.C. (2021). Az oktatás nyelvének hatása az iskolákban a diákok teljesítményére: Bizonyítékok Malajziából a szintetikus kontroll módszer alkalmazásával. World Bank Group Policy Research Working Paper 9517. http://hdl.handle.net/10986/35031
Stonewall, J., Fjelstad, K., Dorneich, M., Shenk, L., Krejci, C., & Passe, U. (2017, szeptember). Bevált gyakorlatok az alulreprezentált népességek bevonására. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting (Vol. 61, No. 1, pp. 130–134). Sage CA: Los Angeles, CA: SAGE Publications. https://doi.org/10.1177/1541931213601516
Sutskever, I., Vinyals, O., & Le, Q.V. (2014). Szekvencia-szekvencia tanulás neurális hálózatokkal. Advances in Neural Information Processing Systems 27 (NIPS 2014). https://proceedings.neurips.cc/paper_files/paper/2014/hash/a14ac55a4f27472c5d894ec1c3c743d2-Abstract.html
Ukrajinsʹke nacionalʹne objednannja (2009). Zakarpatsʹke UNO obicjaje vlasnymy sylamy protydijaty separatystam [Kárpátaljai Ukrán Nemzeti Szervezet ígéretet tesz, hogy saját erővel száll szembe a szeparatistákkal május 1-jén] Letöltve: 2023. június 10., innen: https://zaxid.net/zakarpatske_uno_obitsyaye_vlasnimi_silami_protidiyati_separatistam_1_travnya_n1076607
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., & Polosukhin, I. (2017). A figyelem minden, amire szükséged van. NIPS’17: Proceedings of the 31st International Conference on Neural Information Processing Systems, 6000–6010. https://dl.acm.org/doi/10.5555/3295222.3295349
White, D.J., & Overdeer, D. (2020). Az etnikai hovatartozás kihasználása az orosz hibrid fenyegetésekben. Strategos: Scientific journal of the Croatian Defence Academy 4(1), 31–49. https://hrcak.srce.hr/242087
Wiktorek, A.C. (2010). Kárpátaljai ruszinok: Az identitás versengő napirendjei. Washington, D.C.: Georgetown University. https://repository.library.georgetown.edu/handle/10822/552816
Willner, P. (2017). A krónikus enyhe stressz (CMS) depresszió modellje: Története, értékelése és használata. Neurobiology of Stress, 6, 78–93. https://doi.org/10.1016/j.ynstr.2016.08.002
Vélemény, hozzászólás?